Virtuoso Eclipse RDF4J and
- What is Eclipse RDF4J
- What is the Virtuoso Eclipse RDF4J Provider
- Setup
- Getting Started
- Creating a Virtuoso Repository RDF object
- Creating a Virtuoso Repository Connection
- Adding RDF to Virtuoso
- Querying Virtuoso
- Evaluating a SELECT Query
- Evaluating a CONSTRUCT query
- Javadoc API Documentation
- Related
What is Eclipse RDF4J
Eclipse RDF4J (formerly known as OpenRDF Sesame) is an open source Java framework for storing, querying, and reasoning with RDF and RDF Schema. It can be used as a database for RDF and RDF Schema, or as a Java library for applications that need to work with RDF internally. For example, suppose you need to read a big RDF file, find the relevant information for your application, and use that information. Eclipse RDF4J provides you with the necessary tools to parse, interpret, query, and store all this information, embedded in your own application if you want, or, if you prefer, in a separate database or even on a remote server. More generally: Eclipse RDF4J provides an application developer with a toolbox that contains useful hammers, screwdrivers, etc., for 'Do-It-Yourself' projects with RDF.
What is the Virtuoso Eclipse RDF4J Provider
The Virtuoso Eclipse RDF4J Provider is a fully operational Native Graph Model Storage Provider for the Eclipse RDF4J Framework, allowing users of Virtuoso to leverage the Eclipse RDF4J framework to modify, query, and reason with the Virtuoso quad store using the Java language. The Eclipse RDF4J Repository API offers a central access point for connecting to the Virtuoso quad store. Its purpose is to provides a Java-friendly access point to Virtuoso. It offers various methods for querying and updating the data, while abstracting the details of the underlying machinery. The Providers have been tested against the latest currently available versions — Eclipse RDF4J 2.1 and the older Sesame 2.6.x, 2.7.x, 2.8.x, 4.x releases.
Fig. 1 Eclipse RDF4J Component Stack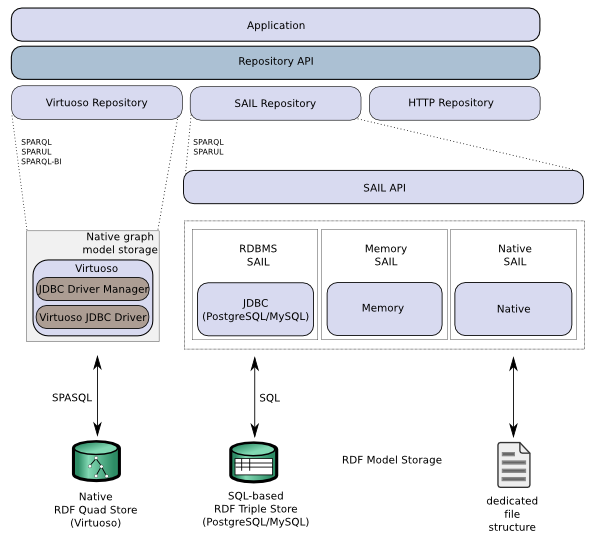
If you need more information about how to set up your environment for working with the Eclipse RDF4J APIs, take a look at Chapter 2 of the Sesame User Guide, Setting up to use the Sesame libraries.
Setup
Required Files
This tutorial assumes you have Virtuoso server installed and that the database is accessible on the default SQL port1111, i.e., localhost:1111.
In addition, the relevant version of the Virtuoso Eclipse RDF4J Provider, and Eclipse RDF4J framework need to be installed.You should download the Virtuoso Eclipse RDF4J Provider JAR archive for the version of Eclipse RDF4J being used, Virtuoso JDBC Driver, Eclipse RDF4J Framework and associated classes and sample programs from our download page.
Note the version of the Eclipse RDF4J Provider (virt_rdf4j.jar or virt_sesameX.jar) can be determined with the commands:
$ java -jar virt_rdf4j.jar OpenLink Virtuoso(TM) Provider for RDF4J(TM) Version 2.0.1 [Build 1.1] $ java -jar virt_sesame2.jar OpenLink Virtuoso(TM) Provider for Sesame2(TM) Version 2.6.5 [Build 1.7] $ java -jar virt_sesame4.jar OpenLink Virtuoso(TM) Provider for Sesame4(TM) Version 4.0.0 [Build 0.1] $
Eclipse RDF4J Provider and Testsuite
Preparation
- Extract the Virtuoso RDF4J Provider and testsuite archive rdf4j_provider.zip.
- Open terminal session and go to the extracted
rdf4j_providerdirectory. - Ensure, that you have a Java JDK1.8.x installation with the command:
$ java -version - Ensure that the
rdf4j_provider/libdirectory lib contains the requiredvirtjdbc4_2.jarVirtuoso JDBC Driver JAR file. If not it can be obtained from, virtjdbc4_2.jar.
Compilation
Rebuild Virtuoso RDF4J provider file virt_rdf4j.jar with the ./gradlew clean Build -x test command:
$ ./gradlew clean Build -x test Downloading https://services.gradle.org/distributions/gradle-3.2.1-bin.zip . . . Unzipping /Users/hwilliams/.gradle/wrapper/dists/gradle-3.2.1-bin/erlz51pt56t1o6vc7t39cikug/gradle-3.2.1-bin.zip to /Users/hwilliams/.gradle/wrapper/dists/gradle-3.2.1-bin/erlz51pt56t1o6vc7t39cikug Set executable permissions for: /Users/hwilliams/.gradle/wrapper/dists/gradle-3.2.1-bin/erlz51pt56t1o6vc7t39cikug/gradle-3.2.1/bin/gradle Starting a Gradle Daemon (subsequent builds will be faster) :clean UP-TO-DATE :compileJava Download https://jcenter.bintray.com/org/slf4j/slf4j-api/1.7.18/slf4j-api-1.7.18.pom Download https://jcenter.bintray.com/org/slf4j/slf4j-parent/1.7.18/slf4j-parent-1.7.18.pom Download https://jcenter.bintray.com/org/eclipse/rdf4j/rdf4j-runtime/2.1.4/rdf4j-runtime-2.1.4.pom . . . Download https://jcenter.bintray.com/org/apache/httpcomponents/httpcore-nio/4.4.4/httpcore-nio-4.4.4.jar Download https://jcenter.bintray.com/org/slf4j/slf4j-api/1.7.21/slf4j-api-1.7.21.jar Download https://jcenter.bintray.com/commons-io/commons-io/2.5/commons-io-2.5.jar :processResources :classes :jar :assemble :copyLibs ------COPY JARS---------- :check :build BUILD SUCCESSFUL Total time: 1 mins 13.624 secs $ $ ls -ltr total 152 drwxr-xr-x@ 4 hwilliams staff 136 22 Dec 10:37 src -rw-r--r--@ 1 hwilliams staff 182 22 Dec 10:37 settings.gradle -rw-r--r--@ 1 hwilliams staff 2176 22 Dec 10:37 gradlew.bat -rwxr-xr-x@ 1 hwilliams staff 5299 22 Dec 10:37 gradlew drwxr-xr-x@ 3 hwilliams staff 102 22 Dec 10:37 gradle drwxr-xr-x@ 4 hwilliams staff 136 22 Dec 10:37 RDF4J_UI drwxr-xr-x@ 4 hwilliams staff 136 22 Dec 10:40 lib -rw-r--r--@ 1 hwilliams staff 2668 22 Dec 13:41 build.gradle drwxr-xr-x 7 hwilliams staff 238 23 Dec 15:14 build -rw-r--r--@ 1 hwilliams staff 56844 23 Dec 15:14 virt_rdf4j.jar $
Testing
By default the Testsuite will try connect to a Virtuoso instance on the localhost:1111 using the dba/dba uid/pwd.
If an instance running with different values is then used to edit the ./build.gradle file, set accordingly:
.
test {
systemProperty 'test_hostname', 'localhost'
systemProperty 'test_port', '1111'
systemProperty 'test_uid', 'dba'
systemProperty 'test_pwd', 'dba'
testLogging.showStandardStreams = true
afterTest { desc, result ->
println "Executing test ${desc.name} [${desc.className}] with result: ${result.resultType}"
}
}
.
Run the RDF4J provider testsuite with the ./gradlew clean testClasses test command:
$ ./gradlew clean testClasses test
:clean
:compileJava
:processResources
:classes
:compileTestJava
Download https://jcenter.bintray.com/junit/junit/4.12/junit-4.12.pom
Download https://jcenter.bintray.com/org/hamcrest/hamcrest-core/1.3/hamcrest-core-1.3.pom
Download https://jcenter.bintray.com/org/hamcrest/hamcrest-parent/1.3/hamcrest-parent-1.3.pom
Download https://jcenter.bintray.com/junit/junit/4.12/junit-4.12.jar
Download https://jcenter.bintray.com/org/hamcrest/hamcrest-core/1.3/hamcrest-core-1.3.jar
Note: Some input files use or override a deprecated API.
Note: Recompile with -Xlint:deprecation for details.
:processTestResources
:testClasses
:test
testsuite.Test_BNode > test1 STANDARD_ERROR
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
testsuite.Test_BNode > test1 STANDARD_OUT
Test with One Row operation (BNode as Virtuoso Native BNode)
Insert data with BNodes
Inserted data:
(t:s1, t:p, _:nodeID://b26807) [test:blank]
(_:nodeID://b26808, t:p, t:o1) [test:blank]
Got bn1=_:nodeID://b26807
Got bn2=_:nodeID://b26808
Try hasStatement with BNodes
hasStatement with bn1 OK
hasStatement with bn2 OK
Try getStatements with BNodes
getStatements with bn1 OK
getStatements with bn2 OK
Try remove with BNodes
After remove triple:
(_:nodeID://b26808, t:p, t:o1) [test:blank]
remove with bn1 OK
After remove triple:
remove with bn2 OK
Insert data with BNode bn1 again (new BNode ID must be assigned)
Inserted data:
(t:s1, t:p, _:nodeID://b26809) [test:blank]
Got bnew=_:nodeID://b26809
Executing test test1 [testsuite.Test_BNode] with result: SUCCESS
testsuite.Test_BNode > test2 STANDARD_OUT
Test with One Row operation (BNode as Virtuoso IRI)
Insert data with BNodes
Inserted data:
(t:s1, t:p, _:node1b4m6bs5rx3) [test:blank]
(_:node1b4m6bs5rx4, t:p, t:o1) [test:blank]
Got bn1=_:node1b4m6bs5rx3
Got bn2=_:node1b4m6bs5rx4
Try hasStatement with BNodes
hasStatement with bn1 OK
hasStatement with bn2 OK
Try getStatements with BNodes
getStatements with bn1 OK
getStatements with bn2 OK
Try remove with BNodes
After remove triple:
(_:node1b4m6bs5rx4, t:p, t:o1) [test:blank]
remove with bn1 OK
After remove triple:
remove with bn2 OK
Executing test test2 [testsuite.Test_BNode] with result: SUCCESS
testsuite.Test_BNode > test3 STANDARD_OUT
Test with Batch Operation (BNode as Virtuoso Native BNode)
Insert data with BNodes
Inserted data:
(_:nodeID://b26810, t:p1, t:o1) [test:blank]
(_:nodeID://b26810, t:p2, _:nodeID://b26811) [test:blank]
(_:nodeID://b26811, t:p3, t:o3) [test:blank]
Got ba=_:nodeID://b26810
Got bb=_:nodeID://b26811
Try hasStatement with BNodes
hasStatement with ba OK
hasStatement with ba & bb OK
hasStatement with ba OK
Try getStatements with BNodes
getStatements with ba OK
getStatements with ba & bb OK
getStatements with bn2 OK
Try remove with BNodes
After remove 2 triple:
(_:nodeID://b26811, t:p3, t:o3) [test:blank]
remove with ba OK
remove with ba & bb OK
After remove triple:
remove with bb OK
Executing test test3 [testsuite.Test_BNode] with result: SUCCESS
testsuite.Test_BNode > test4 STANDARD_OUT
Test with Batch Operation (BNode as Virtuoso IRI)
Insert data with BNodes
Inserted data:
(_:node1b4m6bs5rx7, t:p1, t:o1) [test:blank]
(_:node1b4m6bs5rx7, t:p2, _:node1b4m6bs5rx8) [test:blank]
(_:node1b4m6bs5rx8, t:p3, t:o3) [test:blank]
Got ba=_:node1b4m6bs5rx7
Got bb=_:node1b4m6bs5rx8
Try hasStatement with BNodes
hasStatement with ba OK
hasStatement with ba & bb OK
hasStatement with ba OK
Try getStatements with BNodes
getStatements with ba OK
getStatements with ba & bb OK
getStatements with bn2 OK
Try remove with BNodes
After remove 2 triple:
(_:node1b4m6bs5rx8, t:p3, t:o3) [test:blank]
remove with ba OK
remove with ba & bb OK
After remove triple:
remove with bb OK
Executing test test4 [testsuite.Test_BNode] with result: SUCCESS
testsuite.Test_BNode > test5 STANDARD_OUT
Test Import data from File (BNode as Virtuoso Native BNode)
Insert data with BNodes from file sp2b.n3
Time :1911 ms
Inserted :50168 triples
Try getStatements with BNodes
BNodes loaded OK
Got =["Rajab Sikora"^^<http://www.w3.org/2001/XMLSchema#string>]
for BNode:_:nodeID://b30524
Got =["Yukari Pitcairn"^^<http://www.w3.org/2001/XMLSchema#string>]
for BNode:_:nodeID://b30525
Got =["Reyes Kluesner"^^<http://www.w3.org/2001/XMLSchema#string>]
for BNode:_:nodeID://b30526
Executing test test5 [testsuite.Test_BNode] with result: SUCCESS
testsuite.Test_BNode > test6 STANDARD_OUT
Test Import data from File (BNode as Virtuoso Native BNode)
Insert data with BNodes from file sp2b.n3
Time :1514 ms
Inserted :50168 triples
Try getStatements with BNodes
BNodes loaded OK
Got =["Rajab Sikora"^^<http://www.w3.org/2001/XMLSchema#string>]
for BNode:_:nodeID://b34722
Got =["Yukari Pitcairn"^^<http://www.w3.org/2001/XMLSchema#string>]
for BNode:_:nodeID://b34723
Got =["Reyes Kluesner"^^<http://www.w3.org/2001/XMLSchema#string>]
for BNode:_:nodeID://b34724
Executing test test6 [testsuite.Test_BNode] with result: SUCCESS
Executing test test1 [testsuite.Test_BNode_perf1] with result: SKIPPED
Executing test test2 [testsuite.Test_BNode_perf1] with result: SKIPPED
Executing test test1 [testsuite.VirtuosoTest] with result: SUCCESS
testsuite.VirtuosoTest > test2 STANDARD_OUT
Loading data from URL: http://dbpedia.org/data/Berlin.rdf
Clearing triple store
Executing test test2 [testsuite.VirtuosoTest] with result: SUCCESS
testsuite.VirtuosoTest > test3 STANDARD_OUT
Execute query with parameter binding
Executing test test3 [testsuite.VirtuosoTest] with result: SUCCESS
testsuite.VirtuosoTest > test4 STANDARD_OUT
Loading UNICODE single triple
Executing test test4 [testsuite.VirtuosoTest] with result: SUCCESS
testsuite.VirtuosoTest > test5 STANDARD_OUT
Loading single triple
Casted value type
Selecting property
Statement exists (by resultset size)
Retrieving statement (http://myopenlink.net/dataspace/person/kidehen http://myopenlink.net/foaf/name null)
Writing the statements to file: (/var/folders/51/ptp74p5x175_pgrdcz3pn85c0000gn/T/results.n33643690314785712247txt)
Retrieving graph ids
Retrieving triple store size
Sending ask query
Sending construct query
Sending describe query
Executing test test5 [testsuite.VirtuosoTest] with result: SUCCESS
testsuite.VirtuosoTest > test6 STANDARD_OUT
Retrieving namespaces
Executing test test6 [testsuite.VirtuosoTest] with result: SUCCESS
BUILD SUCCESSFUL
Total time: 59.181 secs
$
Java API Docs
Create the ./gradlew javadoc, which will create the file in the doc directory:
$ ./gradlew javadoc :compileJava UP-TO-DATE :processResources UP-TO-DATE :classes UP-TO-DATE :javadoc :copyDocs ------COPY DOCS---------- BUILD SUCCESSFUL Total time: 2.09 secs $ ls -ltr doc total 352 drwxr-xr-x 3 hwilliams staff 102 23 Dec 15:48 virtuoso -rw-r--r-- 1 hwilliams staff 12808 23 Dec 15:48 stylesheet.css -rw-r--r-- 1 hwilliams staff 827 23 Dec 15:48 script.js -rw-r--r-- 1 hwilliams staff 51 23 Dec 15:48 package-list -rw-r--r-- 1 hwilliams staff 8191 23 Dec 15:48 overview-tree.html -rw-r--r-- 1 hwilliams staff 4185 23 Dec 15:48 overview-summary.html -rw-r--r-- 1 hwilliams staff 929 23 Dec 15:48 overview-frame.html -rw-r--r-- 1 hwilliams staff 2843 23 Dec 15:48 index.html -rw-r--r-- 1 hwilliams staff 92894 23 Dec 15:48 index-all.html -rw-r--r-- 1 hwilliams staff 8246 23 Dec 15:48 help-doc.html -rw-r--r-- 1 hwilliams staff 5568 23 Dec 15:48 deprecated-list.html -rw-r--r-- 1 hwilliams staff 7023 23 Dec 15:48 constant-values.html -rw-r--r-- 1 hwilliams staff 2136 23 Dec 15:48 allclasses-noframe.html -rw-r--r-- 1 hwilliams staff 2376 23 Dec 15:48 allclasses-frame.html $
Sesame 4 Sample Program
Compilation
- Ensure that full paths to the following files, or equivalents for your version of Sesame, are all included in the active
CLASSPATHsetting --openrdf-sesame-4.0.0-onejar.jarslf4j-api-1.7.10.jarcommons-io-2.4.jarvirtjdbc4.jarvirt_sesame4.jar
- Execute the following command --
javac VirtuosoTest.java- Note: we recommend adding the following to the connect string, to use
utf-8androw-auto-commit:
"/charset=UTF-8/log_enable=2"
-- i.e., inVirtuosoTest.java, the line --
Repository repository = new VirtuosoRepository("jdbc:virtuoso://" + sa[0] + ":" + sa[1], sa[2], sa[3]);
-- should become --
Repository repository = new VirtuosoRepository("jdbc:virtuoso://" + sa[0] + ":" + sa[1]+ "/charset=UTF-8/log_enable=2", sa[2], sa[3]);
- Note: we recommend adding the following to the connect string, to use
Testing
- Ensure that full paths to the following files are all included in the active
CLASSPATHsetting (note the addition ofvirtuoso_driver, here) --openrdf-sesame-4.0.0-onejar.jarslf4j-api-1.7.10.jarcommons-io-2.4.jarvirtjdbc4.jarvirt_sesame4.jarvirtuoso_driver
- Run the
VirtuosoTestprogram to test the Sesame 2 Provider with the following command --
java VirtuosoTest <hostname> <port> <uid> <pwd> - The test run should look like this --
$ java VirtuosoTest localhost 1111 dba dba == TEST 1: : Start == TEST 1: : End PASSED: TEST 1 == TEST 2: : Start Loading data from URL: http://dbpedia.org/data/Berlin.rdf log4j:WARN No appenders could be found for logger (org.openrdf.rio.RDFParserRegistry). log4j:WARN Please initialize the log4j system properly. == TEST 2: : End PASSED: TEST 2 == TEST 3: : Start Clearing triple store == TEST 3: : End PASSED: TEST 3 == TEST 4: : Start Loading data from file: virtuoso_driver/data.nt == TEST 4: : End PASSED: TEST 4 == TEST 5: : Start Loading UNICODE single triple == TEST 5: : End PASSED: TEST 5 == TEST 6: : Start Loading single triple == TEST 6: : End PASSED: TEST 6 == TEST 7: : Start Casted value type == TEST 7: : End PASSED: TEST 7 == TEST 8: : Start Selecting property == TEST 8: : End PASSED: TEST 8 == TEST 9: : Start Statement does not exists == TEST 9: : End PASSED: TEST 9 == TEST 10: : Start Statement exists (by resultset size) == TEST 10: : End PASSED: TEST 10 == TEST 11: : Start Statement exists (by hasStatement()) == TEST 11: : End PASSED: TEST 11 == TEST 12: : Start Retrieving namespaces == TEST 12: : End PASSED: TEST 12 == TEST 13: : Start Retrieving statement (http://myopenlink.net/dataspace/person/kidehen http://myopenlink.net/foaf/name null) == TEST 13: : End PASSED: TEST 13 == TEST 14: : Start Writing the statements to file: (/Users/hwilliams/src/git/vos-7-develop/binsrc/sesame4/results.n3.txt) == TEST 14: : End PASSED: TEST 14 == TEST 15: : Start Retrieving graph ids == TEST 15: : End PASSED: TEST 15 == TEST 16: : Start Retrieving triple store size == TEST 16: : End PASSED: TEST 16 == TEST 17: : Start Sending ask query == TEST 17: : End PASSED: TEST 17 == TEST 18: : Start Sending construct query == TEST 18: : End PASSED: TEST 18 == TEST 19: : Start Sending describe query == TEST 19: : End PASSED: TEST 19 ============================ PASSED:19 FAILED:0
Sesame 2 Sample Program
Compilation
- Ensure that full paths to the following files, or equivalents for your version of Sesame, are all included in the active
CLASSPATHsetting --openrdf-sesame-2.1.2-onejar.jarslf4j-api-1.5.0.jarslf4j-jdk14-1.5.0.jarcommons-io-2.0.jarvirtjdbc3.jarvirt_sesame2.jar
- Execute the following command --
javac VirtuosoTest.java- Note: we recommend adding the following to the connect string, to use
utf-8androw-auto-commit:
"/charset=UTF-8/log_enable=2"
-- i.e., inVirtuosoTest.java, the line --
Repository repository = new VirtuosoRepository("jdbc:virtuoso://" + sa[0] + ":" + sa[1], sa[2], sa[3]);
-- should become --
Repository repository = new VirtuosoRepository("jdbc:virtuoso://" + sa[0] + ":" + sa[1]+ "/charset=UTF-8/log_enable=2", sa[2], sa[3]);
- Note: we recommend adding the following to the connect string, to use
Testing
- Ensure that full paths to the following files are all included in the active
CLASSPATHsetting (note the addition ofvirtuoso_driver, here) --openrdf-sesame-2.1.2-onejar.jarslf4j-api-1.5.0.jarslf4j-jdk14-1.5.0.jarcommons-io-2.0.jarvirtjdbc3.jarvirt_sesame2.jarvirtuoso_driver
- Run the
VirtuosoTestprogram to test the Sesame 2 Provider with the following command --
java VirtuosoTest <hostname> <port> <uid> <pwd> - The test run should look like this --
$ java VirtuosoTest localhost 1111 dba dba == TEST 1: : Start Loading data from URL: http://www.openlinksw.com/dataspace/person/kidehen@openlinksw.com/foaf.rdf == TEST 1: : End PASSED: TEST 1 == TEST 2: : Start Clearing triple store == TEST 2: : End PASSED: TEST 2 == TEST 3: : Start Loading data from file: virtuoso_driver/data.nt == TEST 3: : End PASSED: TEST 3 == TEST 4: : Start Loading UNICODE single triple == TEST 4: : End PASSED: TEST 4 == TEST 5: : Start Loading single triple == TEST 5: : End PASSED: TEST 5 == TEST 6: : Start Casted value type == TEST 6: : End PASSED: TEST 6 == TEST 7: : Start Selecting property == TEST 7: : End PASSED: TEST 7 == TEST 8: : Start Statement does not exists == TEST 8: : End PASSED: TEST 8 == TEST 9: : Start Statement exists (by resultset size) == TEST 9: : End PASSED: TEST 9 == TEST 10: : Start Statement exists (by hasStatement()) == TEST 10: : End PASSED: TEST 10 == TEST 11: : Start Retrieving namespaces == TEST 11: : End PASSED: TEST 11 == TEST 12: : Start Retrieving statement (http://myopenlink.net/dataspace/person/kidehen http://myopenlink.net/foaf/name null) == TEST 12: : End PASSED: TEST 12 == TEST 13: : Start Writing the statements to file: (/Users/src/virtuoso-opensource/binsrc/sesame2/results.n3.txt) == TEST 13: : End PASSED: TEST 13 == TEST 14: : Start Retrieving graph ids == TEST 14: : End PASSED: TEST 14 == TEST 15: : Start Retrieving triple store size == TEST 15: : End PASSED: TEST 15 == TEST 16: : Start Sending ask query == TEST 16: : End PASSED: TEST 16 == TEST 17: : Start Sending construct query == TEST 17: : End PASSED: TEST 17 == TEST 18: : Start Sending describe query == TEST 18: : End PASSED: TEST 18 ============================ PASSED:18 FAILED:0
Getting Started
This section covers the essentials for connecting to and manipulating data stored in a Virtuoso repository using the Eclipse RDF4J API. More information on the Eclipse RDF4J Framework, including extended examples on how to use the API, can be found in the Eclipse RDF4J Programmers guide.
The interfaces for the Repository API can be found in packages virtuoso.rdf4j.driver and org.openrdf.repository.
Several implementations for these interfaces exist in the Virtuoso Provider download package.
The Javadoc reference for the Eclipse RDF4J API is available online and can also be found in the doc directory of the download.
Creating a Virtuoso Repository RDF object
The first step to connecting to Virtuoso through the Sesame API is to create a Repository for it. The Repository object operates on (stacks of) Sail object(s) for storage and retrieval of RDF data.
One of the simplest configurations is a repository that just stores RDF data in main memory, without applying any inference. This is also by far the fastest type of repository that can be used. The following code creates and initialize a non-inferencing main-memory repository:
import virtuoso.rdf4j.driver.VirtuosoRepository;
Repository myRepository = VirtuosoRepository("jdbc:virtuoso://localhost:1111","dba","dba");
myRepository.initialize();
The constructor of the VirtuosoRepository class accepts the JDBC URL of the Virtuoso engine, and the username and password of an authorized user.
Following this example, the repository needs to be initialized to prepare the Sail(s) that it operates on, which includes performing operations such as restoring previously stored data, setting up connections to a relational database, etc.
The repository that is created by the above code is volatile: its contents are lost when the object is garbage collected or when the program is shut down. This is fine for cases where, for example, the repository is used as a means for manipulating an RDF model in memory.
Creating a Virtuoso Repository Connection
Now that we have created a VirtuosoRepository object instance, we want to do something with it.
This is achieved through the use of the VirtuosoRepositoryConnection class, which can be created by the VirtuosoRepository class.
A VirtuosoRepositoryConnection represents — as the name suggests — a connection to the actual Virtuoso quad store.
We can issue operations over this connection, and close it when we are done to make sure we are not keeping resources unnecessarily occupied.
In the following sections, we will show some examples of basic operations using the Northwind dataset.
Adding RDF to Virtuoso
The Repository implements the Sesame Repository API, which offers various methods for adding data to a repository. Data can be added programmatically by specifying the location of a file that contains RDF data, and statements can be added individually or in collections.
We perform operations on the repository by requesting a RepositoryConnection from the repository, which returns a VirtuosoRepositoryConnection object.
On this VirtuosoRepositoryConnection object we can perform the various operations, such as query evaluation; getting, adding, or removing statements; etc.
The following example code adds two files, one local and one located on the Web, to a repository:
import org.openrdf.repository.RepositoryException;
import org.openrdf.repository.Repository;
import org.openrdf.repository.RepositoryConnection;
import org.openrdf.rio.RDFFormat;
import java.io.File;
import java.net.URL;
File file = new File("/path/to/example.rdf");
String baseURI = "http://example.org/example/localRDF";
try {
RepositoryConnection con = myRepository.getConnection();
try {
con.add(file, baseURI, RDFFormat.RDFXML);
URL url = new URL("http://example.org/example/remoteRDF");
con.add(url, url.toString(), RDFFormat.RDFXML);
}
finally {
con.close();
}
}
catch (RepositoryException rex) {
// handle exception
}
catch (java.io.IOEXception e) {
// handle io exception
}
More information on other available methods can be found in the javadoc reference of the RepositoryConnection interface.
Querying Virtuoso
The Repository API has a number of methods for creating and evaluating queries. Three types of queries are distinguished: tuple queries, graph queries, and Boolean queries. The query types differ in the type of results that they produce.
Select Query: The result of a select query is a set of tuples (or variable bindings), where each tuple represents a solution of the query.
This type of query is commonly used to get specific values (URIs, blank nodes, literals) from the stored RDF data.
The method QueryFactory.executeQuery() returns a Value [ ][ ] for SPARQL "SELECT" queries.
The method QueryFactory.executeQuery() also calls the QueryFactory.setResult() which populates a set of tuples for SPARQL "SELECT" queries.
The graph can be retrieved using QueryFactory.getBooleanResult().
Graph Query: The result of a graph query is an RDF graph (or set of statements).
This type of query is very useful for extracting sub-graphs from the stored RDF data, which can then be queried further, serialized to an RDF document, etc.
The method QueryFactory.executeQuery() calls the QueryFactory.setGraphResult() which populates a graph for SPARQL "DESCRIBE" and "CONSTRUCT" queries.
The graph can be retrieved using QueryFactory.getGraphResult().
Boolean Query: The result of a Boolean query is a simple Boolean value, i.e., TRUE or FALSE.
This type of query can be used to check if a repository contains specific information.
The method QueryFactory.executeQuery() calls the QueryFactory.setBooleanResult() which sets a Boolean value for SPARQL "ASK" queries.
The value can be retrieved using QueryFactory.getBooleanResult().
Note: Although Eclipse RDF4J 2 currently supports two query languages: SeRQL and SPARQL, the Virtuoso RDF4J Provider only supports the W3C SPARQL specification at this time.
Evaluating a SELECT Query
To evaluate a tuple query we simply do the following:
import java.util.List;
import org.openrdf.OpenRDFException;
import org.openrdf.repository.RepositoryConnection;
import org.openrdf.query.TupleQuery;
import org.openrdf.query.TupleQueryResult;
import org.openrdf.query.BindingSet;
import org.openrdf.query.QueryLanguage;
try {
RepositoryConnection con = myRepository.getConnection();
try {
String queryString = "SELECT x, y FROM WHERE {x} p {y}";
TupleQuery tupleQuery = con.prepareTupleQuery(QueryLanguage.SPARQL, queryString);
TupleQueryResult result = tupleQuery.evaluate();
try {
// do something with the result
}
finally {
result.close();
}
}
finally {
con.close();
}
}
catch (RepositoryException e) {
// handle exception
}
This evaluates a SPARQL query and returns a TupleQueryResult, which consists of a sequence of BindingSet objects.
Each BindingSet contains a set of pairs called Binding objects.
A Binding object represents a name/value pair for each variable in the query's projection.
We can use the TupleQueryResult to iterate over all results and get each individual result for x and y:
while (result.hasNext()) {
BindingSet bindingSet = result.next();
Value valueOfX = bindingSet.getValue("x");
Value valueOfY = bindingSet.getValue("y");
// do something interesting with the query variable values here
}
As you can see, we retrieve values by name rather than by an index.
The names used should be the names of variables as specified in your query.
The TupleQueryResult.getBindingNames() method returns a list of binding names, in the order in which they were specified in the query.
To process the bindings in each binding set in the order specified by the projection, you can do the following:
List bindingNames = result.getBindingNames();
while (result.hasNext()) {
BindingSet bindingSet = result.next();
Value firstValue = bindingSet.getValue(bindingNames.get(0));
Value secondValue = bindingSet.getValue(bindingNames.get(1));
// do something interesting with the values here
}
It is important to invoke the close() operation on the TupleQueryResult, after we are done with it.
A TupleQueryResult evaluates lazily and keeps resources (such as connections to the underlying database) open.
Closing the TupleQueryResult frees up these resources.
Do not forget that iterating over a result may cause exceptions! The best way to make sure no connections are kept open unnecessarily is to invoke close() in the finally clause.
An alternative to producing a TupleQueryResult is to supply an object that implements the TupleQueryResultHandler interface to the query's evaluate() method.
The main difference is that when using a return object, the caller has control over when the next answer is retrieved, whereas with the use of a handler, the connection simply pushes answers to the handler object as soon as it has them available.
As an example we will use SPARQLResultsXMLWriter, which is a TupleQueryResultHandler implementation that writes SPARQL Results XML documents to an output stream or to a writer:
import org.openrdf.query.resultio.sparqlxml.SPARQLResultsXMLWriter;
FileOutputStream out = new FileOutputStream("/path/to/result.srx");
try {
SPARQLResultsXMLWriter sparqlWriter = new SPARQLResultsXMLWriter(out);
RepositoryConnection con = myRepository.getConnection();
try {
String queryString = "SELECT * FROM WHERE {x} p {y}";
TupleQuery tupleQuery = con.prepareTupleQuery(QueryLanguage.SPARQL, queryString);
tupleQuery.evaluate(sparqlWriter);
}
finally {
con.close();
}
}
finally {
out.close();
}
You can just as easily supply your own application-specific implementation of TupleQueryResultHandler, if desired.
Lastly, an important warning: as soon as you are done with the RepositoryConnection object, you should close it.
Notice that during processing of the TupleQueryResult object (for example, when iterating over its contents), the RepositoryConnection should still be open.
We can invoke con.close() after we have finished with the result.
Evaluating a CONSTRUCT query
The following code evaluates a graph query on a repository:
import org.openrdf.query.GraphQueryResult;
GraphQueryResult graphResult = con.prepareGraphQuery(
QueryLanguage.SPARQL, "CONSTRUCT * FROM {x} p {y}").evaluate();
A GraphQueryResult is similar to TupleQueryResult in that it is an object that iterates over the query results.
However, for graph queries the query results are RDF statements, so a GraphQueryResult iterates over Statement objects:
while (graphResult.hasNext()) {
Statement st = graphResult.next();
// do something with the resulting statement here.
}
The TupleQueryResultHandler equivalent for graph queries is org.openrdf.rio.RDFHandler.
Again, this is a generic interface; each object implementing it can process the reported RDF statements in any way it wants.
All writers from Rio (such as the RDFXMLWriter, TurtleWriter, TriXWriter, etc.) implement the RDFHandler interface.
This allows them to be used in combination with querying quite easily.
In the following example, we use a TurtleWriter to write the result of a SPARQL graph query to standard output in Turtle format:
import org.openrdf.rio.turtle.TurtleWriter;
RepositoryConnection con = myRepository.getConnection();
try {
TurtleWriter turtleWriter = new TurtleWriter(System.out);
con.prepareGraphQuery(QueryLanguage.SPARQL, "CONSTRUCT * FROM WHERE {x} p {y}").evaluate(turtleWriter);
}
finally {
con.close();
}
Again, note that as soon as we are done with the result of the query (either after iterating over the contents of the GraphQueryResult or after invoking the RDFHandler), we invoke con.close() to close the connection and free resources.
Javadoc API Documentation
Javadocs covers the complete set of classes, interfaces, and methods implemented by the provider:
- Javadoc API Documentation for the Eclipse RDF4J 2.x Provider
- Javadoc API Documentation for the Sesame 2.6 Provider
- Javadoc API Documentation for the Sesame 2.7+ Provider
- Javadoc API Documentation for the Sesame 4.x Provider
Related
CategoryRDF CategoryOpenSource CategoryVirtuoso CategoryVOS CategorySesame CategoryDocumentation