
Virtuoso Sponger Nanotation User Guide
- Situation Analysis
- What is Nanotation?
- Why is it important?
- How do I use it?
- Basic Rules (authors and processing engines)
- Examples
- Nanotation Processor Usage
- Virtuoso Sponger Implementation Notes
- Live Examples
- Nanotation generated 5-Star Linked Open Data (via URIBurner - a Nanotation Processor) examples:
- FCT Examples
- Related
Situation Analysis
Since the advent of blogging, it has been clear to everyone that posts require augmentation in order to truly function as rapid-fire meme vectors. For instance, could you imagine early blog posts without tagging?Today, we've evolved from early literal tagging (which didn't scale an iota) to wide use of @handles and #hastags.
Basically, @handles are social network specific HTTP URIs that denote Agents (People, Organizations, and Bots) while #hashtags are HTTP URIs that denote Topics.
Problem
Looking at the picture above, in regards to productively encoding and decoding information via the World Wide Web medium, it should be obvious that @handles and#hashtags are basically the digital equivalents of nouns.
And as a consequence, we are basically trying to replicate the power of natural language sentences without critical components such as verbs (connectors) and adjectives (classifiers).A Solution
Leverage the power of an existing language, based on open standards, that already delivers the power of natural language without being limited by the physical constraints of paper (as a mechanism for sentence persistence and exchange).This is where RDF comes into play. It is an open standards based language for constructing digital sentences that pack the same (or even more power) its natural language equivalents. Through the power of RDF it is possible to create micro-annotations (aka. Nanotations) that are embeddable in any kind of text based documents. Naturally, the aforementioned claim doesn't apply to every RDF notation, which is why RDF-Turtle is the vehicle we've chosen to unleash the full power of RDF and the Semantic Web it enables when digital sentences take the form of Linked Open Data.
What is Nanotation?
Nanotation is a mechanism for using embedded digital sentences to enhance blog posts, forum discussion posts, tweets (and other micro-blogging posts), HTML, and plain text document. In addition, it turns each of the aforementioned document types into end-user oriented conduits for contributing data to public and/or private Linked Open Data clouds, on a piecemeal basis -- i.e., you turn curating and publishing Linked Open Data Cloud into a productive crowd-sourced jigsaw puzzle game.Why is it important?
Being able to say anything, about anything, whenever, and from wherever, in a manner that's both machine and human comprehensible has always sat at the very foundations of the Semantic Web Project's value proposition. Unfortunately, confusion about RDF -- the powerful language that drives the notion of a global Semantic Web -- lead to a general bottom-up misconception whereby most perceive it as a document content format rather that an abstract language (system of signs, syntax, and semantics) exploitable using a wide variety of notations.How do I use it?
Due to the compact nature of RDF-Turtle notation, it is possible to embed RDF statements into any text based content. The only requirements are as follows:- Use the following as a marker for embedded RDF-Turtle based RDF statements:
## Turtle Start ## {Trutle-based-RDF-statements} ## Turtle End ##
- Honor the use of <> to indicate reference identifiers (absolute or relative)
- Optionally treat @handle as an HTTP URIs that denote Agents -- for a given data space (e.g., Twitter, LinkedIn, Facebook, Google+ etc..)
- Optionally tread #hashtag as an HTTP URI that denotes a Topic -- ditto .
Basic Rules (authors and processing engines)
As per natural language sentences we have the following parts:
- Subject -- statement focal point
- Predicate -- connection, association, link
- Object -- value of the connection, association, link.
Each sentence subject, predicate, object is denoted (named or referred to) using an identifier (word, phrase, or term). If you want to generate Linked Data that flows across data spaces your best bet is to denote (refer to) sentence subject, predicate, and object (optionally) using identifiers that function like terms -- by using HTTP URIs.
Use prefixes to shorten RDF-Turtle statements:
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
Enables statements such as:
<> a foaf:Document .
Examples
- Most basic Nanotation:
<> a <#Document> . <> <#topic> <#Nanotation>.
- More sophisticated Nanotation that leverages terms from existing vocabularies:
<> a foaf:Document . <> foaf:topic <#Nanotation> .
- More sophisticated Nanotation that leverages commas and semicolons for statement brevity e.g.
when multiple sentences have a common Subject:
<> a foaf:Document; foaf:topic <#Nanotation>.
- When multiple sentences have a common Subject and Predicate but varying list of Objects:
<> a foaf:Document; foaf:topic <#Nanotation>, <#SemanticWeb>, <#LinkedData>.
- Incorporation of Pronouns into RDF sentence :
<> a foaf:Document . <> foaf:maker [a foaf:Person; foaf:name "Kingsley Idehen" ] .
- Processor (parser) hint markers that help Nanotation processors negate seriously mangled HTML content:
## Turtle Start ## <> a foaf:Document; foaf:topic <#Nanotation>, <#SemanticWeb>, <#LinkedData>. ## Turtle End ##
Nanotation Processor Usage
A nanotation processer is an application or service that's capable of consuming text content enhanced with RDF-Turtle based nanotations. Virtuoso's in-built Linked Data Transformation middleware (aka "Sponger") is an example of an application that supports nanotation. Likewise, our URIBurner service which is a free public service driven by an instance of Virtuoso with the Sponger module enabled:
- When using your own instance of Virtuoso, the Sponger service is invoked via the URL pattern:
http://{cname-of-virtuoso-host-machine}/sponger
- When using the public URIBurner service, the Sponger services is invoked via the URL:
http://linkeddata.uriburner.com/
- Note: Either approach outlined above will lead you to an HTML page that contains an input field into which you can type or paste an HTTP-accessible document URL.
Alternatively you can use the following URI patterns:
http://{cname-of-virtuoso-host-machine}/about/html/{document-http-uri}
In all cases, you will end up with an HTML document that includes RDF statements that describe the processed document in a manner that also reveals all the embedded nanotations.
Virtuoso Sponger Implementation Notes
The Sponger treats resources transferred over HTTP as a duality of both a container document and a primary entity. When a resource is deemed to be an HTML document, the document is treated as the primary entity. Otherwise, where the domain is well known, a custom extractor cartridge populates the primary entity with data arising from API calls and the HTML content is regarded as secondary, relegated to the container document. For example, G+ posts are recognized and the Sponger concentrates on presenting the timestamp, body, tags and links and other features of a post.
When sponging an HTTP resource, multiple extractor cartridges might be brought to bear. Consequently, there may be multiple triples containing the entity's content.
The Turtle Sniffer is implemented as a Metacartridge, i.e it runs after all the extractor cartridges have run, augmenting data in the graph. It uses SPARQL inference to collate predicates that constitute "content" for this purpose, along with the HTTP request content (if any), flattening each to plain text.
Currently, the list of potential content predicates is:
-
bibo:content(e.g. arising from the HTML+Variants extractor cartridge) -
bibo:abstract -
oplgplus:annotation(used by Google+ for text when sharing items)
For each of these contents, it checks if it matches the patterns:
## Nanotation Start ## .... ## Nannotation End ##
## Turtle Start ## .... ## Turtle Stop ##
{.... } (note: only applies to tweets on Twitter)
If a content contains one or more nanotation blocks, each block is parsed in turn as Turtle; if not, it attempts to parse the content item as Turtle in entirety.
The HTTP document content is only inspected in case of no triples having been extracted by prior means.
Optionally (enabled by default) each triple may be reified, i.e an rdf:Statement entity created to describe its subject, predicate and object, so you can identify triples arising from nanotations as entities labelled 'Embedded Turtle Statement' and a number in the graph.
Domain-Aware Tag and User Expansion
The Turtle Sniffer expands the patterns #word and @word when they appear in URI (<>) or double quotes (""), in the context of the domain of the URI being sponged.
For example, a Tweet containing the nanotation:
## Nannotation Start ##
<@kidehen> foaf:name "Kingsley Idehen" ;
foaf:knows <@openlink> ;
scot:has_tag <#Data> .
## Nannotation End ##
will be expanded to a Turtle string:
<https://twitter.com/kidehen> foaf:name "Kingsley Idehen" ; foaf:knows <https://twitter.com/openlink> ; scot:has_tag <https://twitter.com/hashtag/Data#this> .
We recognize custom URI formats for users and tags in the contexts of Facebook, Twitter, G+, LinkedIn and Delicious.
Note that the word must appear within quotes; this is to avoid confusion with Turtle's @prefix directive (which is not a user!) and problems that would be caused by performing similar expansions within a quoted sentence.
Live Examples
- RDF statement about Privacy ;
- RDFs usage re. property/predicate description ;
- owl:sameAs relation inserted into a Google+ Post ;
- heavy duty RDF statements in a Facebook post ;
- another Facebook post that puts Ted Nelsons talk on documents and hypertext into contemporary context .
- A tweet reply demonstrating multiple embedded nanotation blocks and tags.
Nanotation generated 5-Star Linked Open Data (via URIBurner - a Nanotation Processor) examples:
- various Nanotations from 28th July 2014 ;
- ditto from 27th July 2014 ;
- ditto from 25th July 2014 .
- A tweet reply demonstrating multiple embedded nanotation blocks and tags.
FCT Examples
- Nanotation based RDF statement that describes Nannotation:
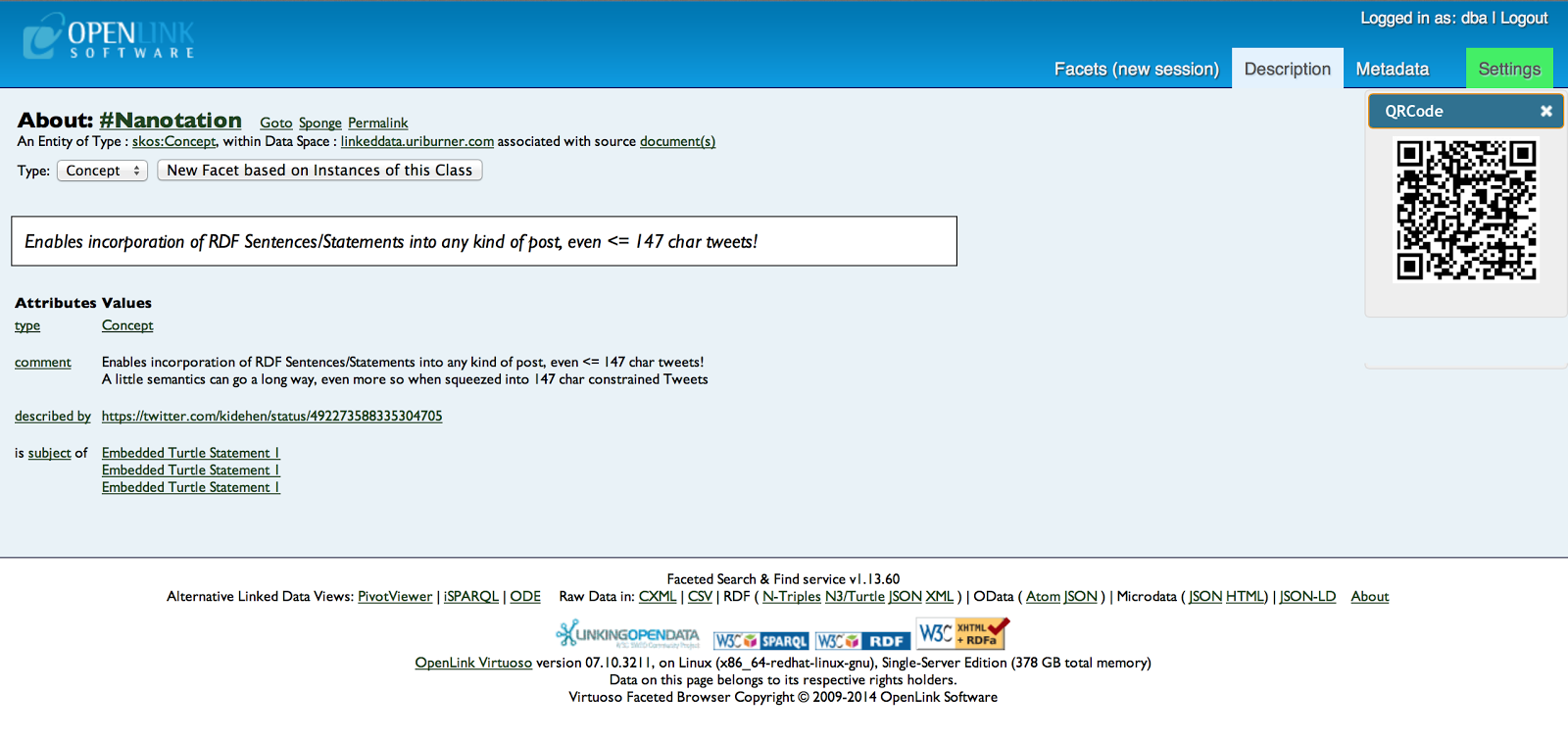
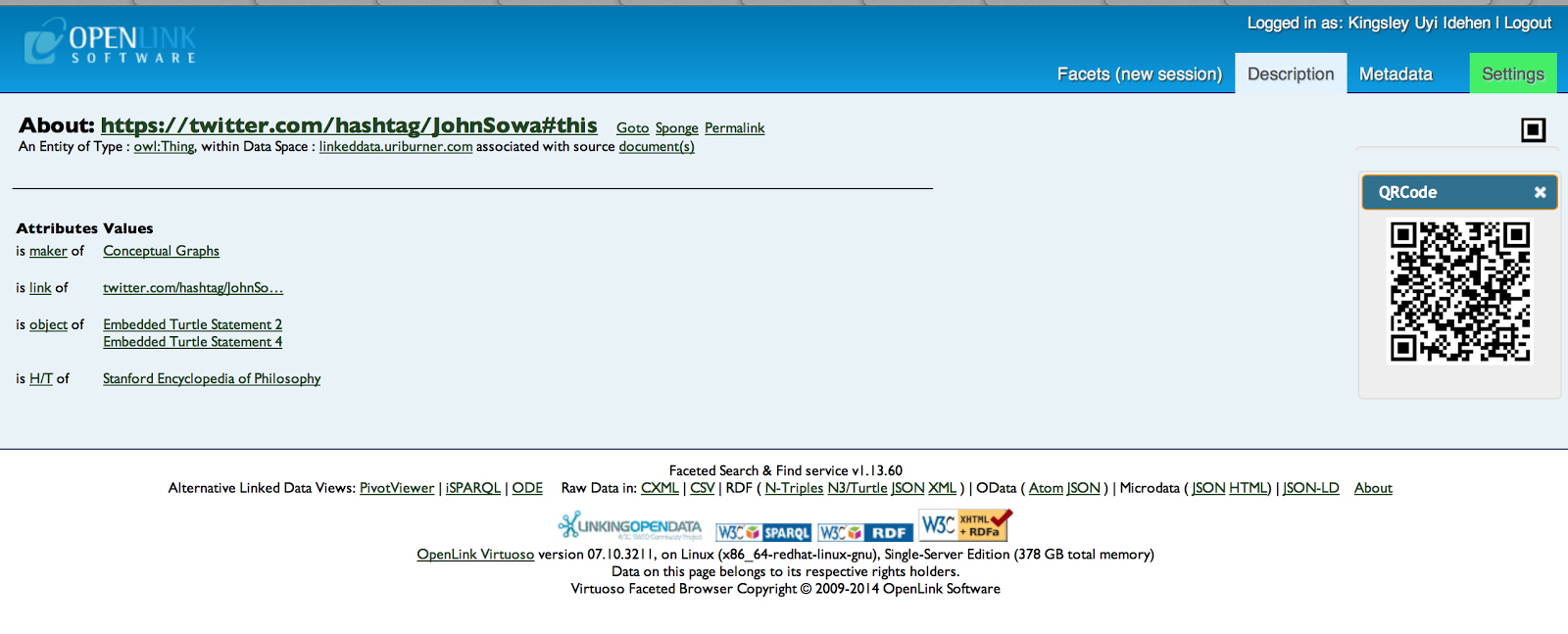
- Nanotation that represents a "Hat Tip" relationship type:
- Nanotation generated RDF statements aggregated by Subject:
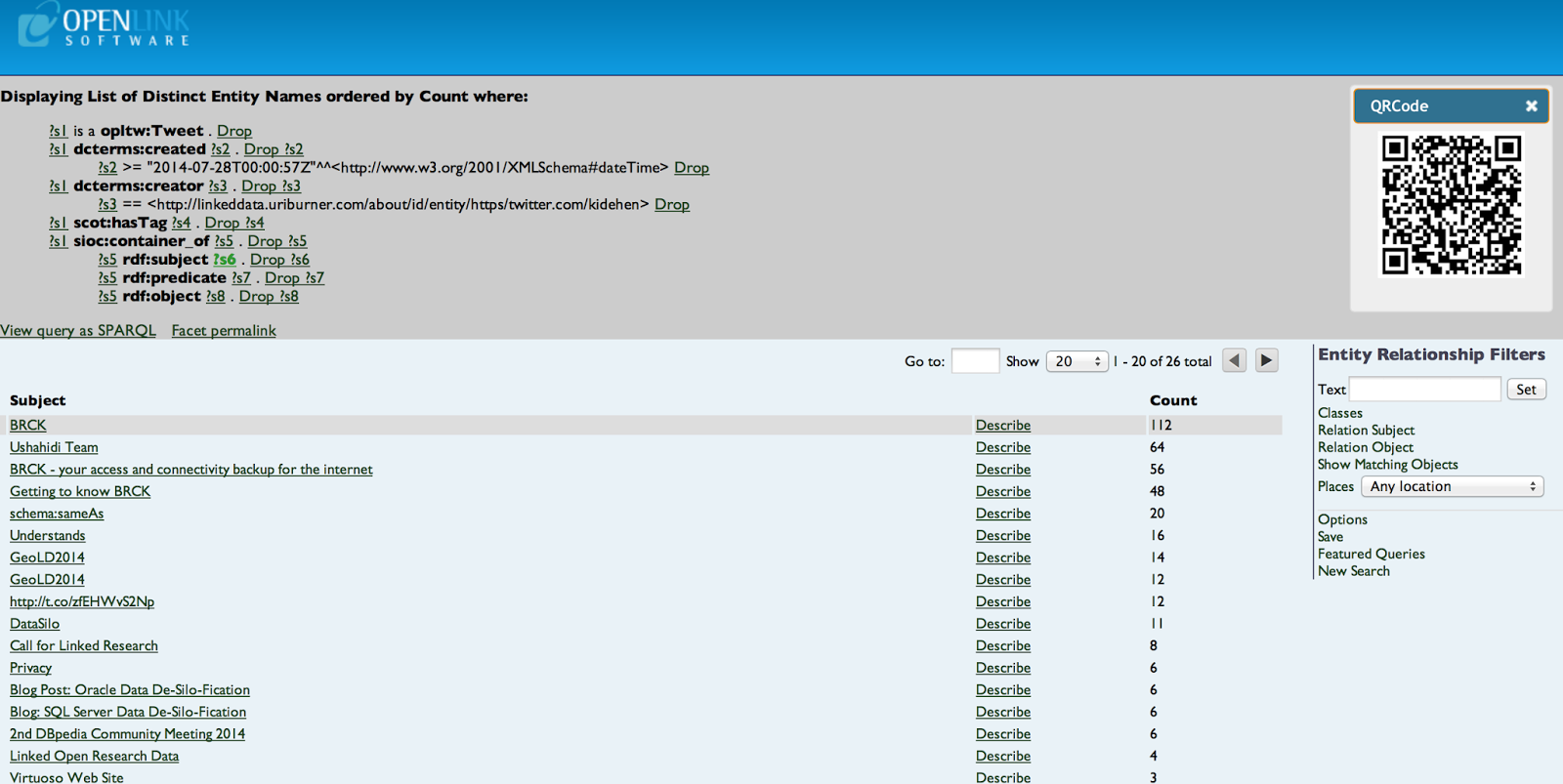
- Nanotation generated RDF statements by Subject:
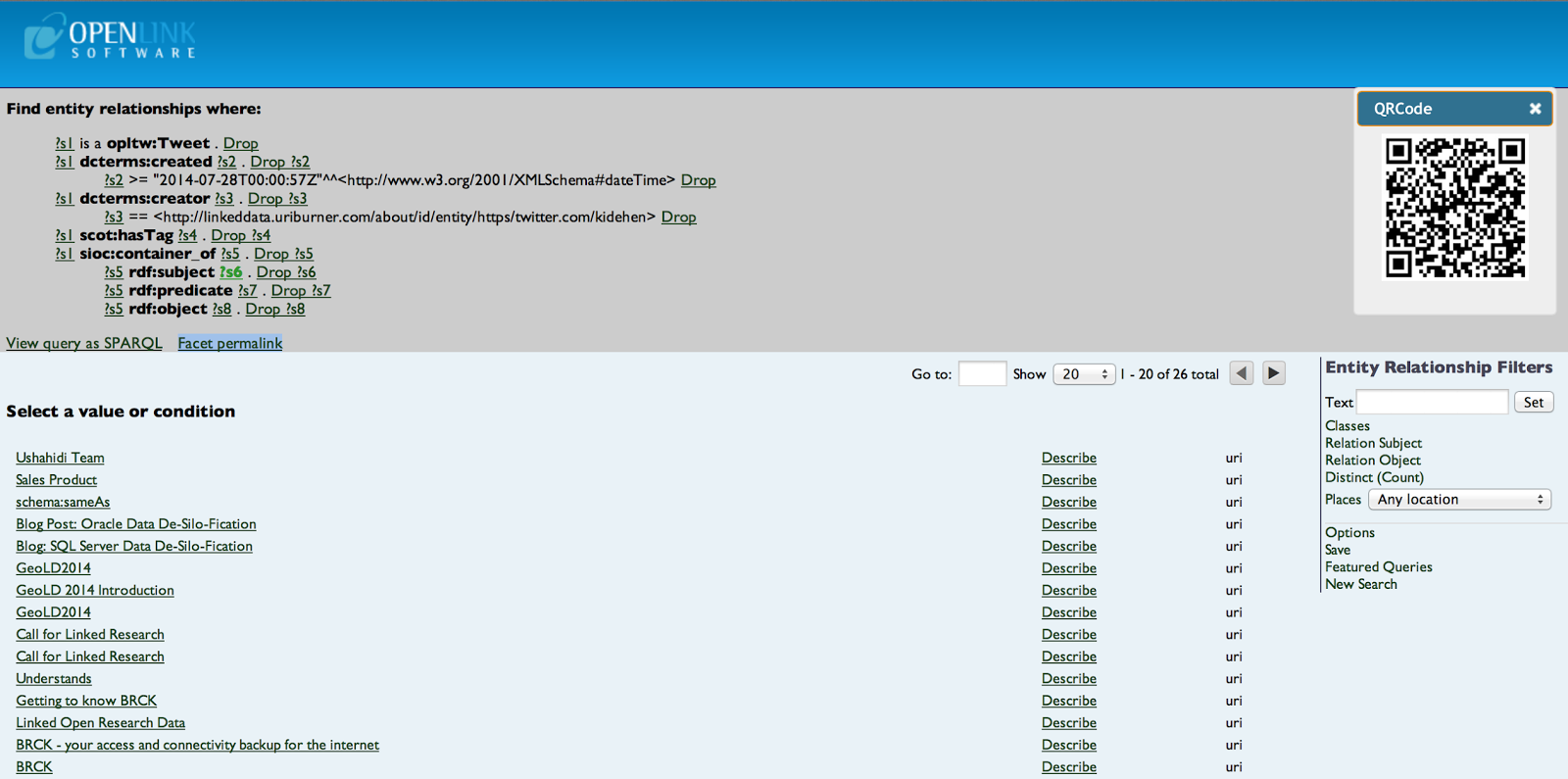
Related
- Virtuoso Sponger RDFization Middleware
- Use Sponger Middleware via REST patterns
- Interact with Sponger Linked Data Middleware via REST patterns
- Setup Virtuoso Sponger Access Control List (ACL)