Deploying Linked Data
v1.2 (Virtuoso 5.0) April 2008
This document describes the process of deploying Linked Data into the existing Web. It discusses some of the difficulties faced in exposing RDF data and in bridging the "Semantic Data-Web" and the traditional "Document Web". Two generic approaches to resolving these deployment challenges are described, content negotiation and URL rewriting, before looking at OpenLink Virtuoso, both from the standpoint of how it implements these solutions and how Linked Data is deployed.
A companion document, Virtuoso Linked Data Views Getting Started Guide?, focuses on Virtuoso Linked Data Views, a facility for exposing relational data as RDF. In addition, it provides useful background information for readers unfamiliar with RDF and outlines some of the key technologies of the Semantic Web.
- Introduction
- What is Linked Data?
- Deployment Challenges
- Data Object Names
- Difficulties with Hash URIs As Data Object Names
- Resolution of the Deployment Challenge
- Content Negotiation
- HttpRange? - 14 Recommendations
- Solving Linked Data Challenges using Content Negotiation
- URL Rewriting
- Deploying Linked Data using Virtuoso
- The Virtuoso Rules-Based URL Rewriter
- Conductor UI for the URL Rewriter
- Virtual Domains (Hosts) & Directories
- "Nice" URLs vs. "Long" URLs
- Rule Processing Mechanics
- Enabling URL Rewriting via the Virtuoso Conductor UI
- Enabling URL Rewriting via Virtuoso PL
- Example - URL Rewriting For the Northwind Linked Data View
- Interacting with Linked Data via RDF Browser
- Interacting with Linked Data via iSPARQL
- Interacting with Linked Data via a standard Document Web Browser
- Northwind URL Rewriting Verification Using curl
- Transparent Content Negotiation
- Transparent Content Negotiation in Virtuoso HTTP Server
- Glossary
- Notes
- Bibliography
- See Also
- Change History
Introduction
The ubiquitous "Web," born as the "World Wide Web," is primarily experienced today as a "Web of Documents," where documents (or Web pages) are connected by simple hypertext links. When you click on a hypertext link within one document, the result is simply that the browser loads (or downloads) the linked document. This widely understood and accepted pattern of interaction with the Web is made possible by two things — the Uniform Resource Identifier, or URI, and the Hypertext Transfer Protocol, or HTTP.
(Uniform Resource Identifier? URI? Don't we mean URL, or Uniform Resource Locator? Yes and no. A Uniform Resource Locator (URL) is a particular kind of Uniform Resource Identifier; a Uniform Resource Name, or URN, is another. As may be obvious from these names, a URL specifies the location of a resource -- like, "the piece of paper centered on the blotter on your desk," or "the third book from the left on the top shelf of the bookcase in the entryway." A URN specifies the name of a resource -- like "your resume," or "the local Chicago telephone directory." Both of these are URIs -- as both can be used to identify the resource in question, at a given moment in time. The piece of paper centered on the blotter on your desk, and where the book is shelved, may change -- and though the URL is the same as what once referred to your resume, the URN is now different, as it is now "the menu for the pizza place down the street," or "the Tom Robbins novel, Still Life With Woodpecker." On the Web, URLs can only lead to HTTP-transmissible documents, so the paper on which your resume is printed cannot actually have a URL -- but the word processing document which was printed on that paper can have a URL. In this example, both the word processing document and the printout are associated with the URN, "your resume," and each is a different representation thereof -- one which is only easily consumable by humans, and one which is easily consumable by humans or machines. URNs are typically less transient, as "your resume" will always mean the same document, but that document's content will change over time -- so increasingly common practice is to have URNs that incorporate some sense of time into the name, often leading to two "special" URNs which are tied to the "first" and the "latest" version of the document. The "first" always leads to the same content -- but the "latest" is obviously likely to change over time.)
The popularity of the current "Document Web" sometimes obscures the fact that from the onset, Tim Berners-Lee envisaged a broader and deeper Web of Linked Data, where URIs weren't simply URLs and therefor limited to association with HTTP-transmissible documents, and where links between resources were not limited to simple hypertext. URNs make it possible to have "hyperdata" links — explicit connections between Named Entities or Data Objects, rather than vague connections between document locations. Hyperdata links include descriptions of the kind of link exposed — such as "the PDF representation of your resume," "the Microsoft Word representation of your resume," "the website of the company at which you worked in 1998 which was named Widgets, Inc." There is no natural requirement that URNs be based on HTTP, but as we discuss below this is necessary to enabling the Web of Linked Data.
This document describes one way to start sprinkling Linked Data into the existing Document Web, gradually bringing the Web closer to Tim Berners-Lee's vision, without breaking its current functionality.
What is Linked Data?
"Linked Data" is the title of a Web Design Issues Note by Berners-Lee that issues a best practice recipe for injecting data into the Web as part of a broader effort to evolve the current Web of interlinked documents to a Web of interlinked data known as the "Semantic Data-Web" (Data-Web). The principles he outlined are paraphrased as:
- Identify things (real or abstract) in your universe-of-discourse (or "data space") using URIs (whether URNs or URLs — each has its place)
- Make each URI (URN, URL, or otherwise) acessible via HTTP, so that people can discover and explore your data spaces via the Web
- Use URIs to expose the context of your data (i.e., describe and provide other information about your data, using URIs)
- Enhance your URIs by adding links to other URIs, enabling discovery of other things on the Web
Deployment Challenges
The Data-Web and the Document Web are two dimensions of the same Web separated by a common element: the URI. On the Document Web, URIs always point to physical resources, while in the Data-Web they point to physical things that are associated with physical and/or abstract things. Of course, this unveils a number of deployment challenges.
Data Object Names
In the current Document Web, resource URIs do not separate identity from representation.
The Document Web assumes that a resource URI points to the location of a physical Web information resource.
The HTTP payload that conveys the "GET" request for a resource also includes a mechanism for defining representation.
Thus, the URI http://demo.openlinksw.com/Northwind/Customer/ALFKI points to the (X)HTML document representation of the physical resource ALFKI located in the directory /Northwind/Customer/ on host machine demo.openlinksw.com that accepts HTTP requests at the default port 80.
The Data-web on the other hand, seeks to use the URI scheme in a manner that separates identity from representation. A URI may simply identify a physical or abstract entity, aka a "data object", and so serve as a unique data object name or ID. Accessing, or de-referencing, the data object returns a representation of the object, not the object itself. (For instance, the object in question may be Paris!)
Unambiguous Reference vs Ambiguous Access
When we refer to, or identify, a data object through a data object name, that reference should be unambiguous. However, when we access (or de-reference) a data object, access is inherently ambiguous. Accessing an abstract data object relies on materialization of a description of the entity in a form compatible with the transmission medium. As the object may have many possible descriptions (facets), the act of accessing it is ambiguous.
URIs As Unique Data Object Names
Thus, unlike in the Document Web, in the Semantic Web the same URI http://demo.openlinksw.com/Northwind/Customer/ALFKI cannot serve as both the identity and representation of the Customer ALFKI.
The Linked Data provider needs to adhere to a URI based naming convention in order to avoid data access ambiguity.
For example, the URI http://demo.openlinksw.com/Northwind/Customer/ALFKI#this, could always to taken to imply the ID of the Customer data object referred to as ?ALFKI?.
The URI with the #this suffix is a so-called hash URI, which is a convention adopted by some practitioners.
Difficulties with Hash URIs As Data Object Names
In the prior section, we established the need for disambiguating references and accesses to resources via the Data-Web, and highlighted the hash URI scheme as one scheme some practitioners have adopted when using URIs as unique data object names.
However from the perspective of the Data-Web Server (the piece responsible for understanding Reference), the URIs http://demo.openlinksw.com/Northwind/Customer/ALFKI and http://demo.openlinksw.com/Northwind/Customer/ALFKI#this are identical, and thereby inherently ambiguous, because nothing following the fragment identifier, "#", ever leaves the Web Client, due to the fact that the Web Client expects to process "#this" locally, post resource retrieval.
As a result, the Data-Web Server has to figure out how to dereference the Information Resource URI http://demo.openlinksw.com/Northwind/Customer/ALFKI and the Identity URI http://demo.openlinksw.com/Northwind/Customer/ALFKI#this from the HTTP GET request payload that will only predictably contain the URI http://demo.openlinksw.com/Northwind/Customer/ALFKI.
(Even if a Web client knowingly tacks the data following the "#" to the HTTP GET request it has no control over proxies along the way that may strip out "#this".) Likewise, referencing an entity via its identity URI (the act of dereferencing) is only achieved via interaction with an associated Web information resource that "DESCRIBE" the entities in question.
In reality, this associative process is inherently ambiguous and unavoidable.
It is also important to note that descriptive Web information resources can take the form of bona fide parameterized URLs of the kind commonly associated with RESTful Web Services.
Resolution of the Deployment Challenge
To unobtrusively evolve the dominant Document Web usage pattern to a Data-Web usage pattern, the challenges of Data Access and Data Reference need to be resolved using the existing Web infrastructure. The best means of resolution is content negotiation as it provides the foundation for an unobtrusive mechanism known as URL rewriting.
Content Negotiation
Content negotiation is a mechanism defined in the HTTP specification that makes it possible to serve different representations of a document (or any resource) at the same (Note 1) URL, so that software agents can choose which representation best fits their capabilities. The originally conceived need for this mechanism stemmed from mobile phone browsers, which were better suited to smaller page sizes, without many graphics and other niceties of the fully featured Web, often satisfied by a WAP representation. In the world of RDF, a user interacting through a traditional Web browser may want a resource represented in HTML or XHTML, whereas a Semantic Web application would prefer an RDF/XML representation due to its Structured Data orientation.
A browser or any other HTTP based web application indicates it resource representation preferences by packaging these preferences via the "Accept:" headers of each HTTP request.
For example, a browser could send this HTTP request to indicate that it wants an HTML or XHTML version of http://www.openlinksw.com/whitepapers/data_management in English or French:
GET /whitepapers/data_management HTTP/1.1 Host: www.openlinksw.com Accept: text/html, application/xhtml+xml Accept-Language: en, fr
Here, the HTTP Accept header sent by the browser indicates the MIME types it wants (text/html or application/xhtml+xml).
An RDF browser, in contrast, might stipulate a MIME type of application/rdf+xml or application/rdf+n3 to receive a rendering in RDF/XML or N3 respectively.
Rather than returning the content in the required format directly, servers often implement content negotiation by redirecting to a URL where the appropriate representation is found. For example, a server might respond with:
HTTP/1.1 302 Found Location: http://www.openlinksw.com/whitepapers/data_management.en.html
The redirect is indicated by the HTTP status code 302 (Found).
The client would then send another HTTP request to the new URL.
HTTP defines a number of 3xx status codes all of which indicate the client is being redirected.
Instead of 302, servers can also use 303 (See Other) to indicate the response to the request can be found at another location (as expressed via the "Location:" response header).
HttpRange - 14 Recommendations
The problem of URI/resource-type interpretation was originally addressed by the W3C Technical Architecture Group (TAG) around 2005 and was known as the "HttpRange?-14" issue. After a good deal of deliberation, the TAG proposed the guidelines below on the information that can be inferred from the HTTP protocol response codes when dereferencing a URI:
| HTTP Response Code | Material Returned | Inference |
|---|---|---|
200 ( success) | A Resource Representation and its Location | A Web information resource has been located in the desired Representation. |
303 ( see other) | A Resource Location | A redirection to the Location of an associated Web information resource in a desired Representation. |
4XX or 5XX ( error) | Nothing | No Web information resource or Resource Location is discernible from the Resource and Representation combination used in the message. |
Solving Linked Data Challenges using Content Negotiation
Returning to our earlier example URIs (http://demo.openlinksw.com/Northwind/Customer/ALFKI and http://demo.openlinksw.com/Northwind/Customer/ALFKI#this) we can construct a decision table that demonstrates how a deployer of Linked Data would leverage content negotiation en route to alleviating the previously outlined Data Access and Data Reference challenges.
| URI | URI Type | Requested Representation (X)HTML | Requested Representation RDF |
|---|---|---|---|
http://demo.openlinksw.com/Northwind/Customer/ALFKI | Slash based | 406 (Not available or applicable) or 303 (Redirect to an associated resource in requested representation format, e.g., http://demo.openlinksw.com/) | 303 (Redirect to URL of information resource that DESCRIBEs the entity http://demo.openlinksw.com/ in the Data space http://demo.openlinksw.com/) |
http://demo.openlinksw.com/Northwind/Customer/ALFKI#this | Hash based | 200 OK (Since fragment ID component of the URI doesn't affect the URL for the information resource | 200 OK (Return an information resource that DESCRIBEs the entity http://demo.openlinksw.com/ |
URL Rewriting
URL rewriting is the act of modifying a source URL prior to the final processing of that URL by a Web Server.
The ability to rewrite URLs may be desirable for many reasons that include:
- Changing Web information resource URLs on the a Web Server without breaking existing bookmarks held in User Agents (e.g., Web browsers)
- URL compaction where shorter URLs may be constructed on a conditional basis for specific User Agents (e.g., Email clients)
- Construction of search engine friendly URLs that enable richer indexing since most search engines cannot process parameterized URLs effectively.
Using URL Rewriting to Solve Linked Data Deployment Challenges
In the previous section we demonstrated how content negotiation and HTTP response messages could be used to address the data access issues arising from the use of URIs associated with resource identity and representation.
We determined earlier that URI naming schemes don't resolve the challenges associated with referencing data.
To reiterate, this is demonstrated by the fact that the URIs http://demo.openlinksw.com/Northwind/Customer/ALFKI and http://demo.openlinksw.com/Northwind/Customer/ALFKI#this both appear as http://demo.openlinksw.com/Northwind/Customer/ALFKI to the Web Server, since data following the fragment identifier "#" never makes it that far.
The only way to address data referencing is by pre-processing source URIs (e.g., via regular expression or sprintf substitutions) as part of a URL rewriting processing pipeline. The pipeline process has to take the form of a set of rules that cater for elements such as HTTP Accept headers, HTTP response code, HTTP response headers, and rule processing order.
An example of such a pipeline for the hash URI scheme is depicted in the table below:
| URI Source (Regular Expression Pattern) | HTTP Accept Headers (Regular Expression) | HTTP Response Code | HTTP Response Headers | Rule Processing Order |
|---|---|---|---|---|
/Northwind/Customer/([^#]*) | None (meaning default) | 200 or 303 responses depending on the user agent default or server side quality of service rules via Transparent Content Negotiation. | None | Normal (order irrelevant) |
/Northwind/Customer/([^#]*) | (text/rdf.n3) / (application/rdf.xml) | 200 OK and return the information resource that DESCRIBEs the entity identified by the hash URI in the requested representation. | None | Normal (order irrelevant) |
/Northwind/Customer/([^#]*) | (text/html) / (application/xhtml.xml) | 200 OK and return an information resource in requested representation. | None | Normal (order irrelevant) |
A similar pipeline for the slash URI scheme would be:
| URI Source (Regular Expression Pattern) | HTTP Accept Headers (Regular Expression) | HTTP Response Code | HTTP Response Headers | Rule Processing Order |
|---|---|---|---|---|
/Northwind/Customer/([^#]*) | None (meaning default) | 200 or 303 responses depending on the user agent default or server side quality of service rules via Transparent Content Negotiation. | None | Normal (order irrelevant) |
/Northwind/Customer/([^#]*) | (text/rdf.n3) / (application/rdf.xml) | 303 Redirect to an associated URL of an information resource that DESCRIBEs the entity identified by the URI | None | Normal (order irrelevant) |
/Northwind/Customer/([^#]*) | (text/html) / (application/xhtml.xml) | 406 (Not Acceptable) or 303 Redirect to location of resource in requested representation | Vary: negotiate, accept Alternates: {"ALFKI" 0.9 {type application/rdf+xml}} | Last (must be last in processing chain) |
The source URI patterns refer to virtual or physical directories at http://demo.openlinksw.com/.
Rules can be placed at the head or tail of the pipeline, or applied in the order they are declared, by specifying a Rule Processing Order of First, Last, or Normal, respectively.
The decision as to which representation to return for URI http://demo.openlinksw.com/Northwind/Customer/ALFKI is based on the MIME type(s) specified in any Accept header accompanying the request.
In the case of the last rule, the Alternates response header applies only to response code 406.
406 would be returned if there were no (X)HTML representation available for the requested resource.
In the example shown, an alternative representation is available in RDF/XML.
When applied to matching HTTP requests, the last two rules might generate responses similar to those below:
$ curl -I -H "Accept: application/rdf+xml" http://demo.openlinksw.com/Northwind/Customer/ALFKI
HTTP/1.1 303 See Other
Server: Virtuoso/05.00.3016 (Solaris) x86_64-sun-solaris2.10-64 PHP5
Connection: close
Content-Type: text/html; charset=ISO-8859-1
Date: Mon, 16 Jul 2007 22:40:03 GMT
Accept-Ranges: bytes
Location: /sparql?query=CONSTRUCT+{+%3Chttp%3A//demo.openlinksw.com/Northwind/Custom
er/ALFKI%23this%3E+%3Fp+%3Fo+}+FROM+%3Chttp%3A//demo.openlinksw.com/Northwind%3E+WHE
RE+{+%3Chttp%3A//demo.openlinksw.com/Northwind/Customer/ALFKI%23this%3E+%3Fp+%3Fo+}&
format=application/rdf%2Bxml
Content-Length: 0
In the cURL exchange depicted above, the target Virtuoso server redirects to a SPARQL endpoint that retrieves an RDF/XML representation of the requested entity.
$ curl -I -H "Accept: text/html" http://demo.openlinksw.com/Northwind/Customer/ALFKI
HTTP/1.1 406 Not Acceptable
Server: Virtuoso/05.00.3016 (Solaris) x86_64-sun-solaris2.10-64 PHP5
Connection: close
Content-Type: text/html; charset=ISO-8859-1
Date: Mon, 16 Jul 2007 22:40:23 GMT
Accept-Ranges: bytes
Vary: negotiate,accept
Alternates: {"ALFKI" 0.9 {type application/rdf+xml}}
Content-Length: 0
In this second cURL exchange, the target Virtuoso server indicates that there is no resource to deliver in the requested representation. It provides hints in the form of an alternate resource representation and URI that may be appropriate, i.e., an RDF/XML representation of the requested entity.
Deploying Linked Data using Virtuoso
The preceding sections described a generic approach to deploying linked data into the existing Web. We now turn our attention to Virtuoso, to describe its solution for linked data deployment.
In fact, Virtuoso's solution is to implement the generic approach outlined in the prior sections, using the twin pillars of Content Negotiation and URL rewriting.
The Virtuoso Rules-Based URL Rewriter
Virtuoso provides a URL rewriter that can be enabled for URLs matching specified patterns. Coupled with customizable HTTP response headers and response codes, Data-Web server administrators can configure highly flexible rules for driving content negotiation and URL rewriting. The key elements of the URL rewriter are:
- Rewriting rule
- Each rule describes how to parse a single source URL, and how to compose the URL of the page ultimately returned in the "
Location:" response headers - Every rewriting rule is uniquely identified internally (using IRIs).
- Two types of rule are supported, based on the syntax used to describe the source URL pattern matching: sprintf-based and regex-based.
- Rewrite rules list
- A named ordered list of rewrite rules or rule lists where rules of the list are processed from top to bottom or in line with processing pipeline precedence instructions
- Configuration API
- The rewriter configuration API defines functions for creating, dropping, and enumerating rules and rule lists.
- Virtual hosts and virtual paths
- URL rewriting is enabled by associating a rewrite rules list with a virtual directory
Each of these elements is described in more detail below, although complete descriptions of the features or functions in question are not given. The intention here is to provide an overview of Virtuoso's URL rewriting capabilities and their application to deploying linked data. Please refer to the Virtuoso Reference Documentation for full details.
Conductor UI for the URL Rewriter
Virtuoso is a full-blown HTTP server in its own right. The HTTP server functionality co-exists with the product core (i.e., DBMS Engine, Web Services Platform, WebDAV filesystem, and other components of the Universal Server). As a result, it has the ability to multi-home Web domains within a single instance across a variety of domain name and port combinations. In addition, it also enables the creation of multiple virtual directories per domain.
In addition to the basic functionality describe above, Virtuoso facilitates the association of URL Rewriting rules with the virtual directories associated with a hosted Web domain.
In all cases, Virtuoso enables you to configure virtual domains, virtual directories and URL rewrite rules for one or more virtual directories, via the (X)HTML-based Conductor Admin User Interface or a collection of Virtuoso Stored Procedure Language (PL)-based APIs.
Virtual Domains (Hosts) & Directories
A Virtuoso virtual directory maps a logical path to a physical directory that is file system or WebDAV based.
This mechanism allows physical locations to be hidden or simply reorganized.
Virtual directory definitions are held in the system table DB.DBA.HTTP_PATH.
Virtual directories can be administered in three basic ways:
- Using the Visual Administration Interface via a Web browser;
- Using the functions
vhost_define()andvhost_remove(); and - Using SQL statements to directly update the
HTTP_PATHsystem table.
"Nice" URLs vs. "Long" URLs
Although we are approaching the URL Rewriter from the perspective of deploying linked data, the Rewriter was developed with additional objectives in mind. These in turn have influenced the naming of some of the formal argument names in the Configuration API function prototypes. In the following sections, long URLs are those containing a query string with named parameters; nice (aka. source) URLs have data encoded in some other format. The primary goal of the Rewriter is to accept a nice URL from an application and convert this into a long URL, which then identifies the page that should actually be retrieved.
Rule Processing Mechanics
When an HTTP request is accepted by the Virtuoso HTTP server, the received nice URL is passed to an internal path translation function. This function takes the nice URL and, if the current virtual directory has a url_rewrite option set to an existing ruleset name, tries to match the corresponding rulesets and rules; that is, it performs a recursive traversal of any rule-list associated with it. For every rule in the rule-list, the same logic is applied (only the logic for regex-based rules is described; that for sprintf-based rules is very similar):
- The input for the rule is the resource URL as received from the HTTP header, i.e., the portion of the URL from the first solidus ('
/') after thehost:portfields to the end of the URL. - The input is normalized.
- The input is matched against the rule's regex. If the match fails, the rule is not applied and the next rule is tried. If the match succeeds, the result is a vector of values.
- If the URL contains a query string, the names and values of the parameters are decoded by
split_and_decode(). - The names and values of any parameters in the request body are also decoded.
- The destination URL is composed:
- The value of each parameter in the destination URL is taken from (in order of priority):
- the value of a parameter in the match result;
- the value of a named parameter in the query string of the input nice URL;
- if the original request was submitted by the
POSTmethod, the value of a named parameter in the body of thePOSTrequest; or - if a parameter value cannot be derived from one of these sources, the rule is not applied and the next rule is tried.
Note:
The path translation function described above is internal to the Web server, so its signature is not appropriate for Virtuoso/PL calls and thus is not published.
Virtuoso/PL developers can harness the same functionality using the DB.DBA.URLREWRITE_APPLY API call.
Enabling URL Rewriting via the Virtuoso Conductor UI
The steps for configuring URL Rewrite rules via the Virtuoso Conductor are as follows:
- Assuming you are using the local demonstration database, load
http://localhost:8890/conductorinto your browser, and then proceed through the Conductor as follows: - Click the "
WebDAV & HTTP", and "HTTP Hosts & Directories" tabs - Pick the domain that contains the virtual directories to which the rules are to be applied (in this case the default was taken)
- Click on the "
URL-rewrite" link to create, delete, or edit a rule as shown below: - Create a Rule for
HTML Representation Requests (via SPARQL SELECT Query) - Create a Rule for
RDF Representation Requests (via SPARQL CONSTRUCT Query) - Then save and exit the Conductor, and test your rules with
curlor any other User Agent.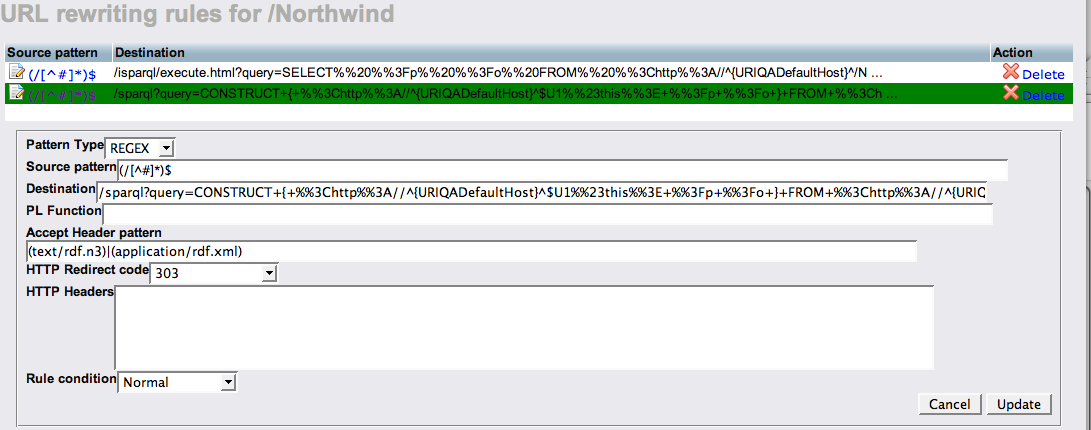
Enabling URL Rewriting via Virtuoso PL
The vhost_define() API is used to define virtual hosts and virtual paths hosted by the Virtuoso HTTP server.
URL rewriting is enabled through this function's opts parameter.
opts is of type ANY, e.g., a vector of field-value pairs.
Numerous fields are recognized for controlling different options.
The field value url_rewrite controls URL rewriting.
The corresponding field value is the IRI of a rule list to apply.
Configuration API
Virtuoso includes the following functions for managing URL rewriting rules and rule lists. The names are self-explanatory.
DB.DBA.URLREWRITE_DROP_RULE— Deletes a rewriting ruleDB.DBA.URLREWRITE_CREATE_SPRINTF_RULE— Creates a rewriting rule which uses sprintf-based pattern matchingDB.DBA.URLREWRITE_CREATE_REGEX_RULE— Creates a rewriting rule which uses regular expression (regex) based pattern matchingDB.DBA.URLREWRITE_DROP_RULELIST— Deletes a rewriting rule listDB.DBA.URLREWRITE_CREATE_RULELIST— Creates a rewriting rule listDB.DBA.URLREWRITE_ENUMERATE_RULES— Lists all the rules whose IRI match the specified 'SQL like' patternDB.DBA.URLREWRITE_ENUMERATE_RULELISTS— Lists all the rule lists whose IRIs match the specified 'SQL like' pattern
Creating Rewriting Rules
Rewriting rules take two forms: sprintf-based or regex-based. When used for nice URL to long URL conversion, the only difference between them is the syntax of format strings. The reverse long to nice conversion works only for sprintf-based rules, whereas regex-based rules are unidirectional.
For the purposes of describing how to make dereferenceable URIs for linked data, we will stick with the nice to long conversion using regex-based rules.
Regex rules are created using the URLREWRITE_CREATE_REGEX_RULE() function.
Function Prototype:
URLREWRITE_CREATE_REGEX_RULE ( rule_iri, allow_update, nice_match, nice_params, nice_min_params, target_compose, target_params, target_expn := null, accept_pattern := null, do_not_continue := 0, http_redirect_code := null );
Parameters:
rule_iri: VARCHAR. The rule's name / identifierallow_update: INTEGER. Indicates whether the rule can be updated.Non-zeroindicates yes;0indicates no. The update is subject to the following rules:- If the given
rule_iriis already in use as a rule list identifier, an error is signaled. - If the given
rule_iriis already in use as a rule identifier andallow_updatefor the existing rule is0, an error is signaled. - If the given
rule_iriis already in use as a rule identifier andallow_updatefor the existing rule is non-zero, the existing rule is updated.
- If the given
nice_match: VARCHAR. A regex match expression to parse the URL into a vector of occurrences.nice_params: ANY. A vector of the names of the parsed parameters. The length of the vector should be equal to the number of '(...)' specifiers in the format string.nice_min_params: INTEGER. Used to specify the minimum number of sprintf format patterns to be matched in order to trigger the given rule. It only affects sprintf rules and has no effect for regex rules.target_compose: VARCHAR. A regex compose expression for the URL of the destination page.target_params: ANY. A vector of names of parameters that should be passed to the compose expression (target_compose) as$1,$2and so on.target_expn: VARCHAR. Optional SQL text that should be executed instead of a regexcomposecall.accept_pattern: VARCHAR. A regex expression to match the HTTPAcceptheaderdo_not_continue: INTEGER. If the given rule satisfies the match conditions,1signifies do not try the next rule from same rule list, and0signifies try the next rule.http_redirect_code: INTEGER.NULLor the integer values301,302,303, or406, are currently allowed. If a3xxredirect code is given, an HTTPredirectresponse will be sent back to client. IfNULLis specified, the server will process the redirect internally.
Example - URL Rewriting For the Northwind Linked Data View
In our Linked Data Views of SQL white paper we covered the process of declaring Linked Data Views of SQL data via the Virtuoso Meta-schema Language. When producing the Linked Data Views we used the Virtuoso "Demo" database, which is very similar to the "Northwind" database that comes as an installation bundle with Microsoft ACCESS and SQL Server.
The Northwind schema is comprised of commonly understood SQL Tables including Customers, Orders, Employees, Products, Product Categories, Shippers, Countries, Provinces, etc.
An Linked Data View of SQL data is an RDF Named Graph (RDF data set) comprised of RDF Linked Data (triples) stored in a Virtuoso Quad Store (the native RDF Data Management realm of Virtuoso).
In the example that follows, we are going interact with Linked Data deployed into the Data-Web from a live instance of Virtuoso, which uses the URL Rewrite rules from the prior section.
The components used in the example are as follows:
- Virtuoso SPARQL Endpoint:
http://demo.openlinksw.com/sparql - Named RDF Graph:
http://demo.openlinksw.com/Northwind - Entity ID -
http://demo.openlinksw.com/Northwind/Customer/ALFKI#this - Information Resource:
http://demo.openlinksw.com/Northwind/Customer/ALFKI - Interactive SPARQL Query Builder (iSPARQL) -
http://demo.openlinksw.com/DAV/JS/isparql/index.html
Interacting with Linked Data via RDF Browser
Steps:
- Start the browser -
http://demo.openlinksw.com/DAV/JS/rdfbrowser/index.html - Enter the Information Resource URI,
http://demo.openlinksw.com/Northwind/Customer/ALFKI, into the input field labeled "URI"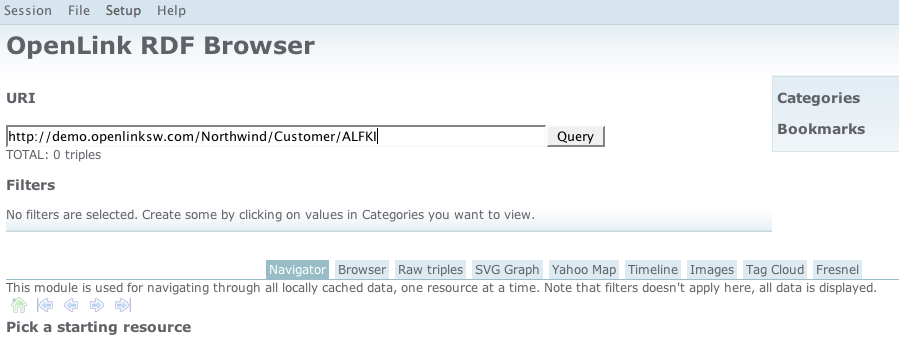
- Click on the "
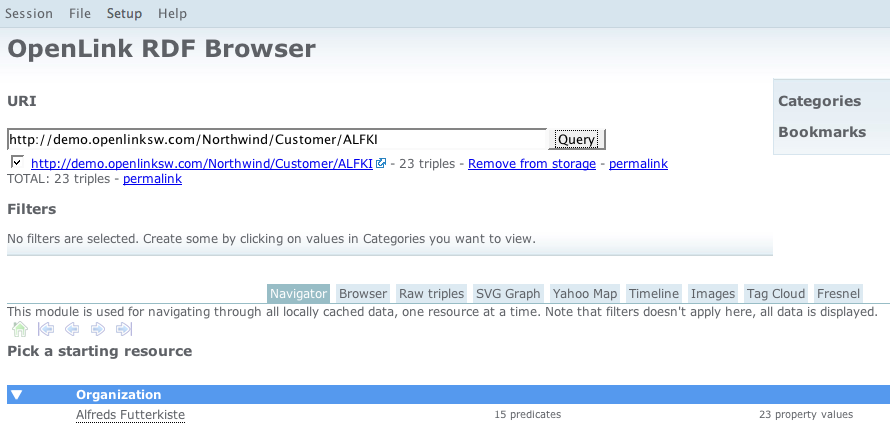
Query" button or simply hit "Enter" after typing (or pasting in) the Information Resource URI - For the purpose of this exercise, view the data returned via the "Navigator" Viewer
- Click on the "
Raw Triples" viewer tab and observe the exposure of the Entityhttp://demo.openlinksw.com/Northwind/Customer/ALFKI#thisvia the Triple based (Subject, Predicate, Object) records in the results table.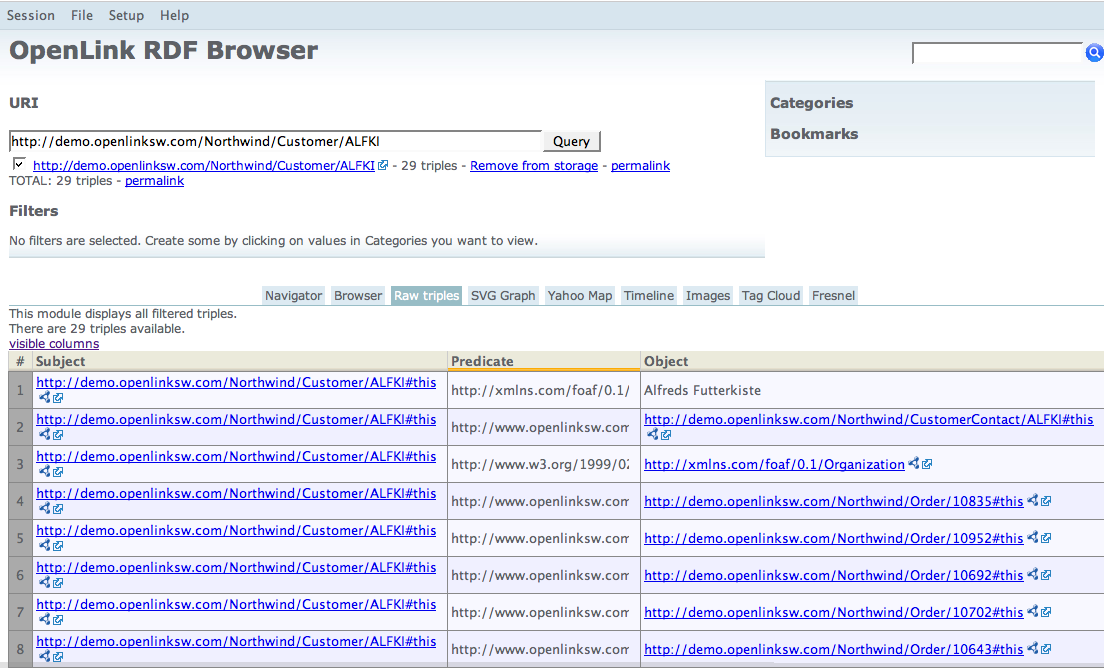
Interacting with Linked Data via iSPARQL
We can interact with the same Information Resource and associated RDF using the iSPARQL Query tool as follows:
- Start the Query Builder by entering the following into your browser:
http://demo.openlinksw.com/isparqlYou will be presented with a default Query By Example (QBE) canvas that includes a default Graph Pattern and a default URI. Change the URI to:http://demo.openlinksw.com/Northwind/Customer/ALFKI(Information Resource as a Data Resource in the context of RDF)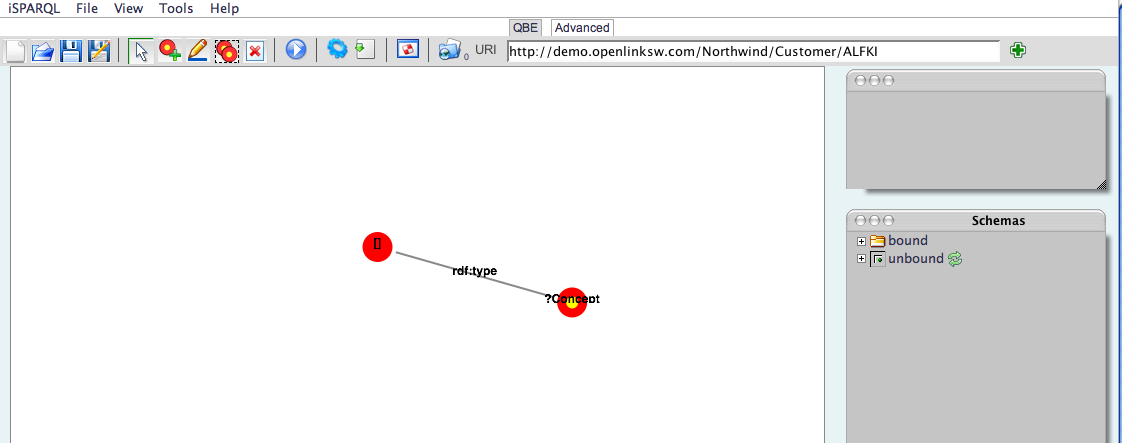
- Then execute the default query (which simply gets a list of concepts), by clicking on the "
>" button. Note: There is a single record in the result table. It indicates that there is a single concept, Organization, as defined by the FOAF schema.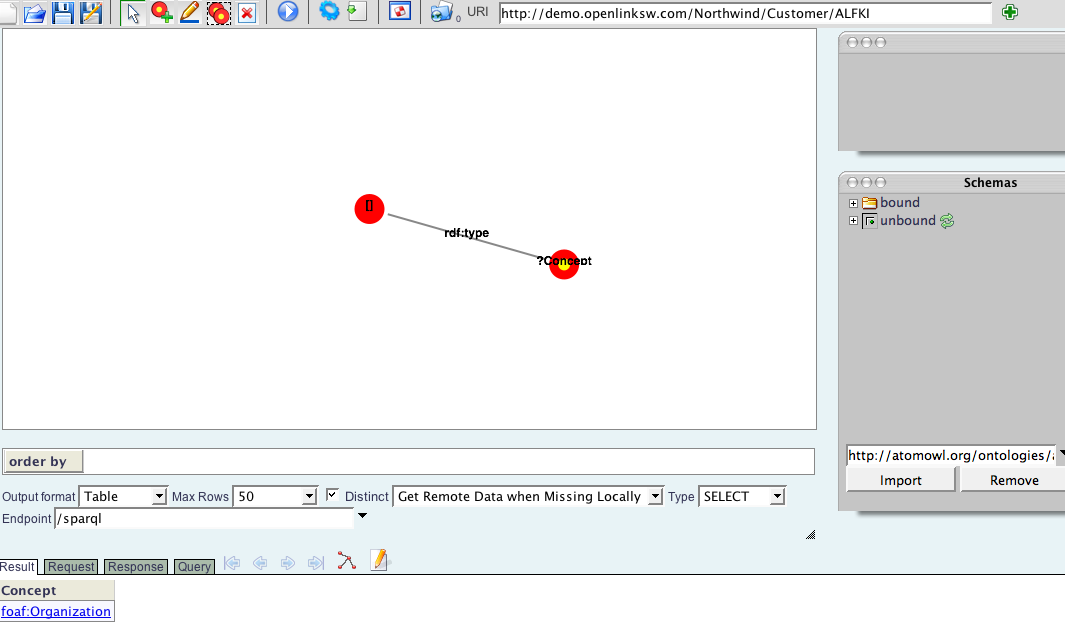
- Click on the
foaf:Organizationrecord, and you will be presented with a Data Web-optimized hyperlink that presents you with three options:Dereference,Explore, and(X)HTML Page Open.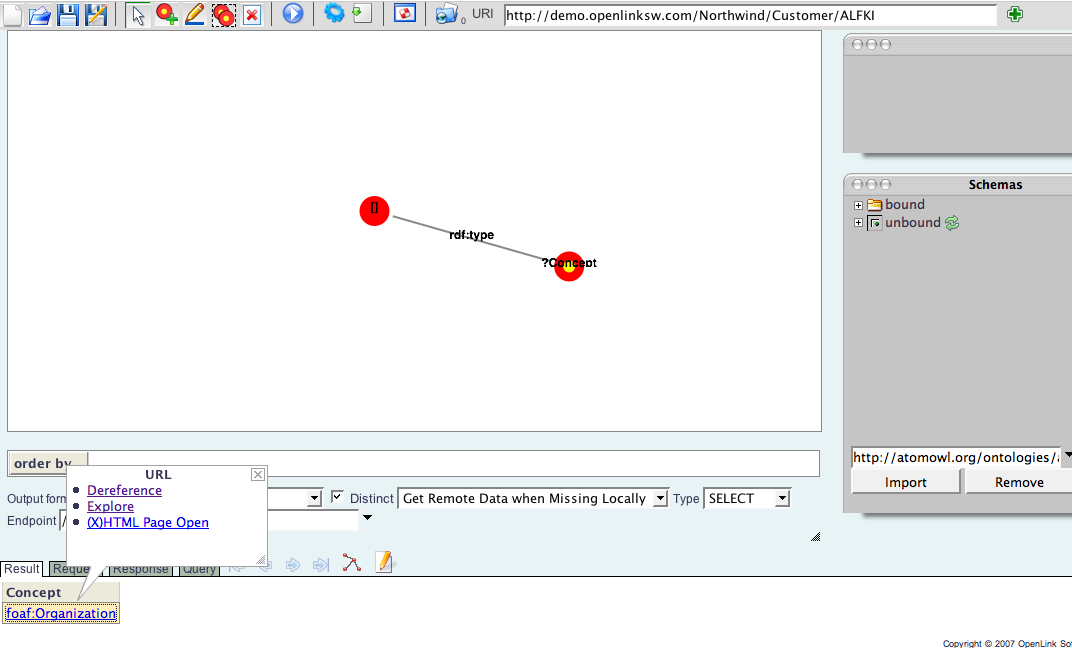
- Click
Explore(since you are interested in "instance data" for thefoaf:Organizationconcept, as opposed to the schema definitions of said concept). You will be presented withhttp://demo.openlinksw.com/Northwind/Customer/ALFKI#thiswhich is an RDF Entity ID of afoaf:Organizationinstance.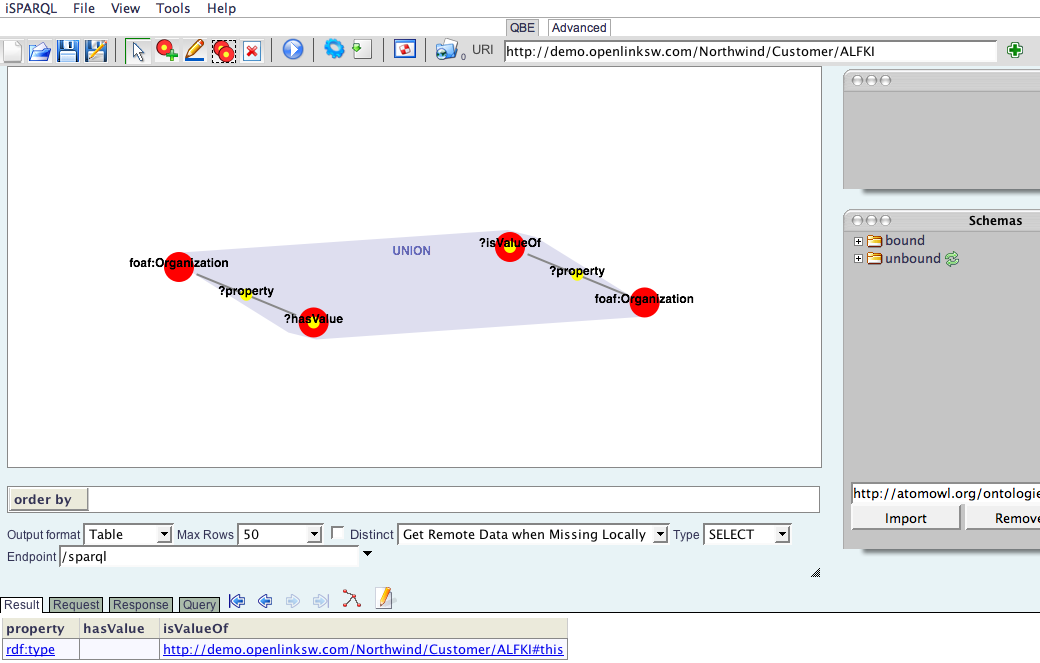
- Click on the
http://demo.openlinksw.com/Northwind/Customer/ALFKIrecord, and you will once again be presented with the enhanced hyperlink and its options. This time, clickDereference, since you are interested in the description of the entityhttp://demo.openlinksw.com/Northwind/Customer/ALFKI, as opposed to all the records in the RDF database that are related to it.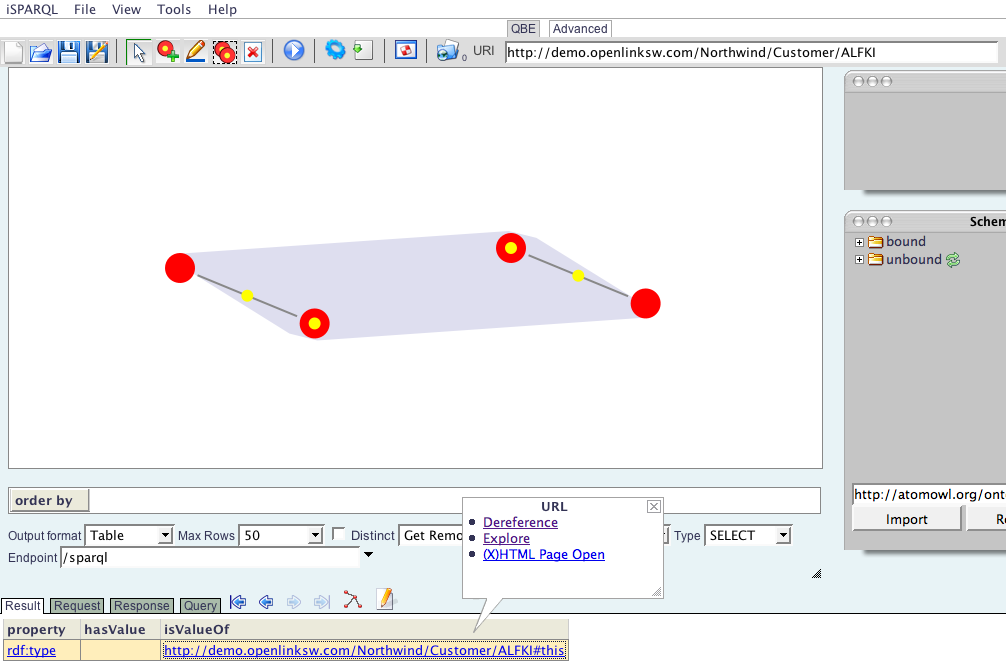
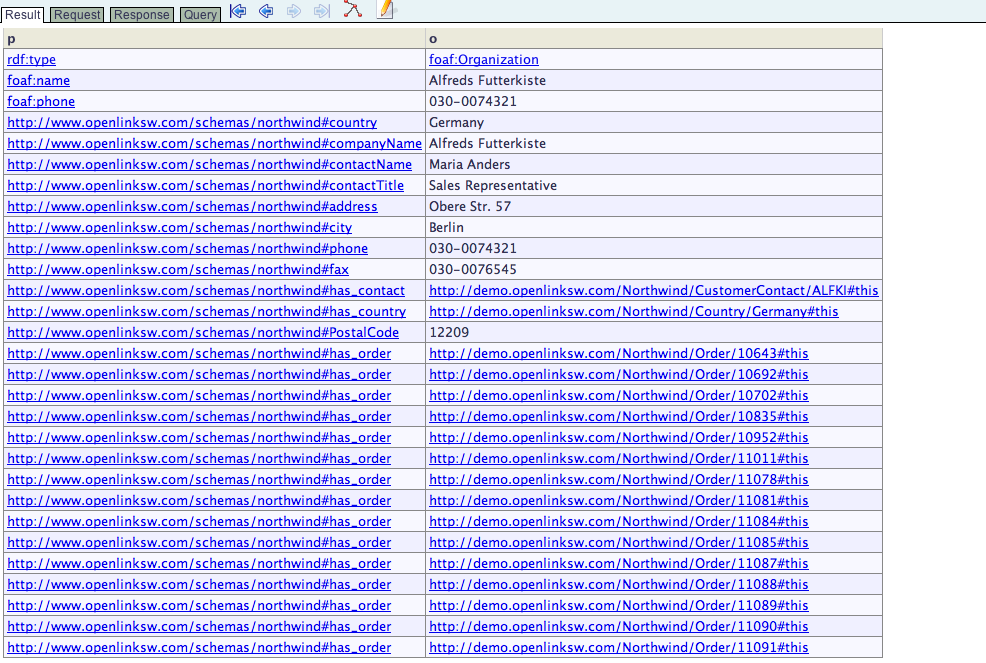
Interacting with Linked Data via a standard Document Web Browser
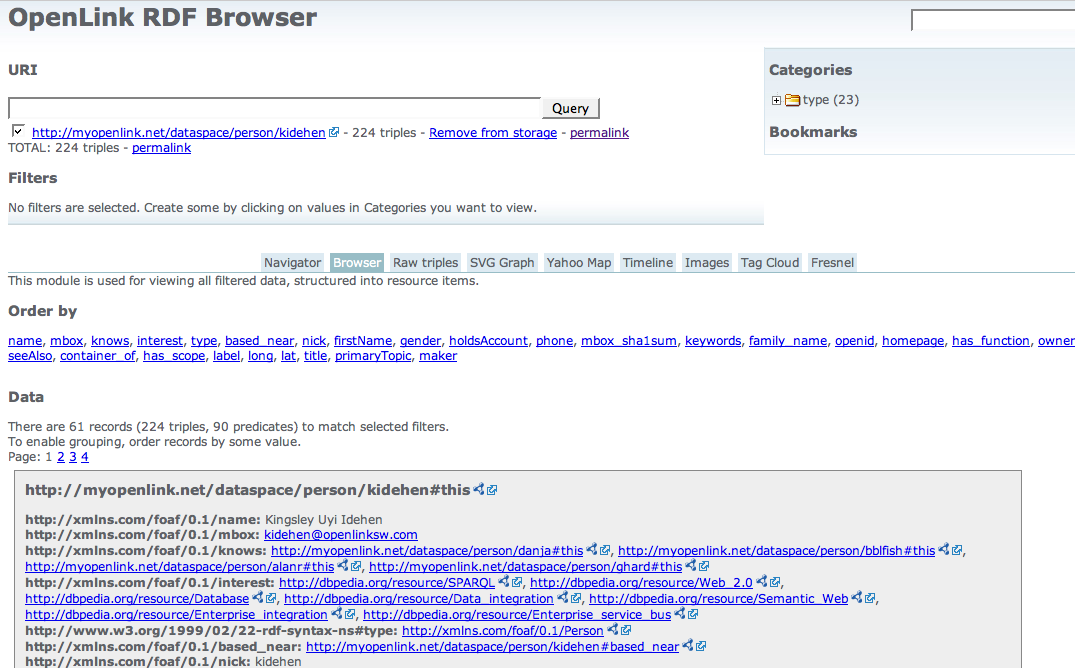
In the prior sections, we used the OpenLink RDF Browser and iSPARQL Query-By-Example tools to interact with RDF Entities via associated Information Resources. Each of these tools includes a Resource Save feature that enables you to save an RDF Browser session or an iSPARQL Query for future reuse. In either scenario the end-product is a Dynamic Linked Data Page — a Web Information Resource (document) that includes links to RDF based Linked Data.
Saved Browser Session
Steps:
- From your RDF Browser session, go to the
Session>>Savemenu item.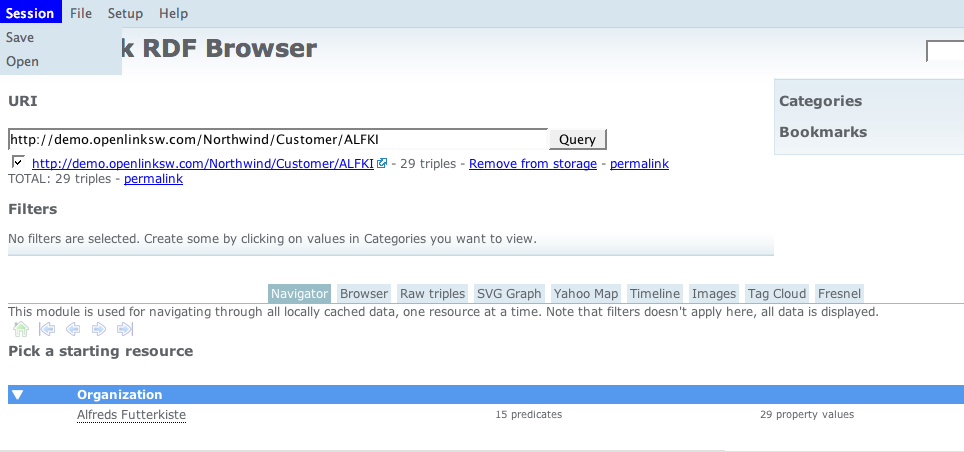
- Select a directory location (note: this is a WebDAV location in the Virtuoso Server) and then enter a file name, e.g.,
ALFKI_Linked_Datay. The saved file will automatically be assigned the extension.wqx.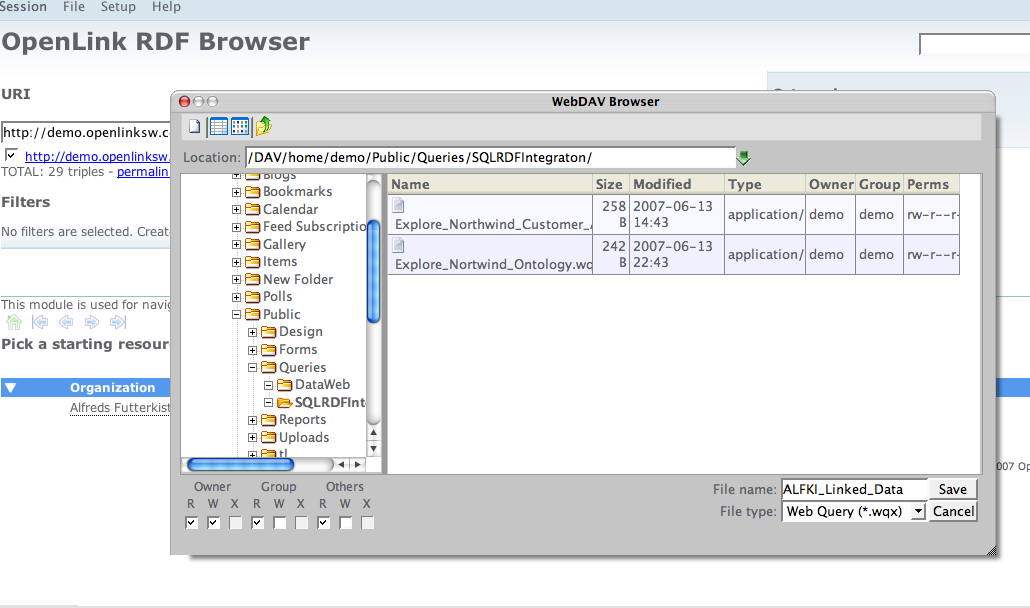
- Open a standard browser instance on your internet device (desktop, notebook, phone, etc.), and enter the URL for the location into which you just saved your browser session, e.g.,
http://demo.openlinksw.com/DAV/home/demo/Public/Queries/SQLRDFIntegraton/(based on our example).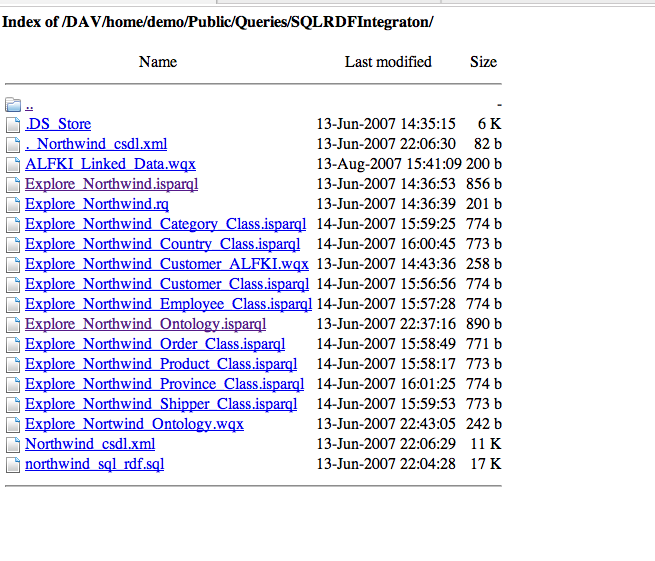
- Click on the file
ALFKI_Linked_Data.wqx, which will then reveal a browser session-oriented Linked Data page.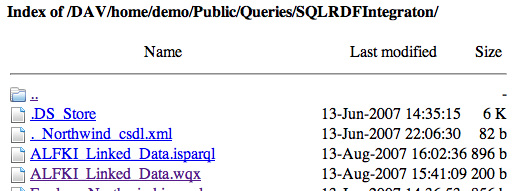
Saved iSPARQL Query
Steps:
- From your iSPARQL Session, pick the
File>>Save(if first time) orFile>>Save As(for saving to different name)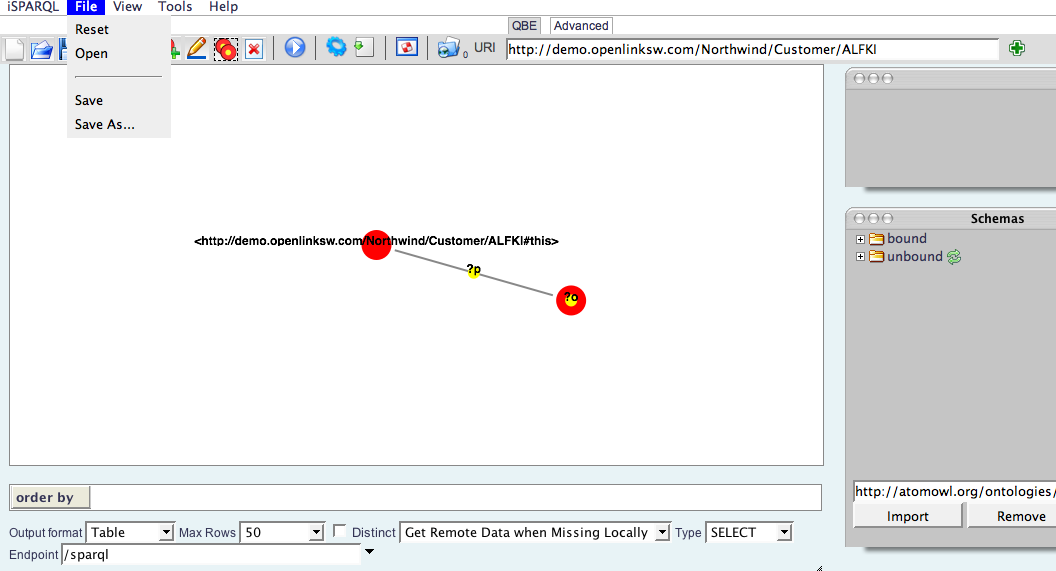
- Type in a name for your saved query, e.g.,
ALFKI_Linked_Data. Note that you have a number of file type options. For this exercise, we are going to choose the.isparqltype, since we are attempting to create a Dynamic Linked Data page.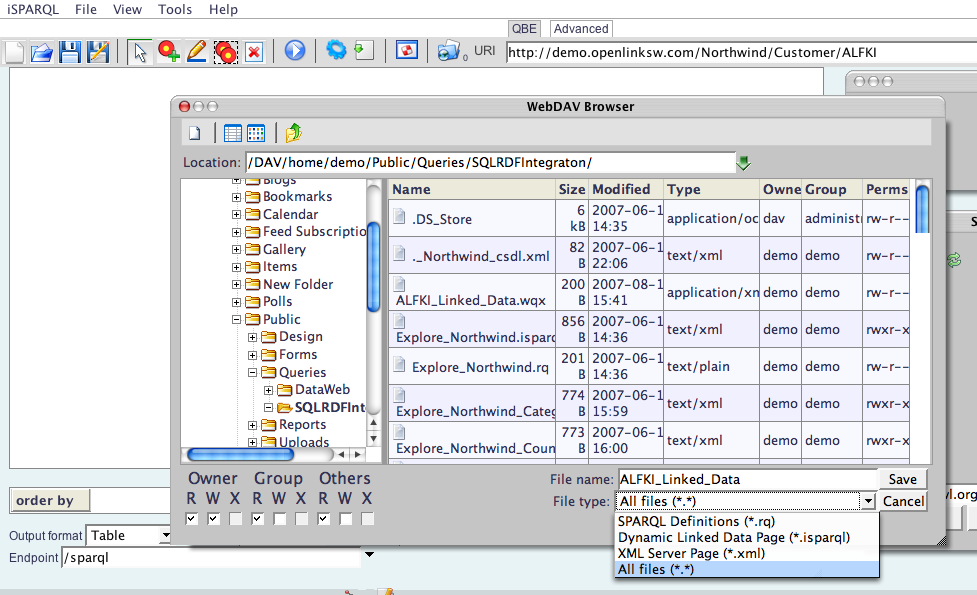
- Open a standard browser instance on your internet device (desktop, notebook, phone, etc.), and enter the URL for the location into which you save your browser session, e.g.,
http://demo.openlinksw.com/DAV/home/demo/Public/Queries/SQLRDFIntegraton/(based on our example).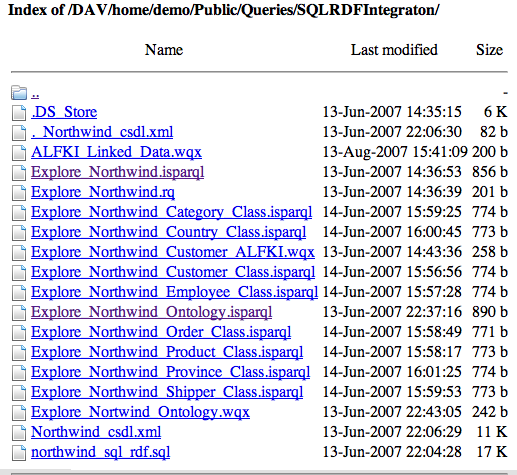
- Click on the file
ALFKI_Linked_Data.isparql, and then interact with the Linked Data page.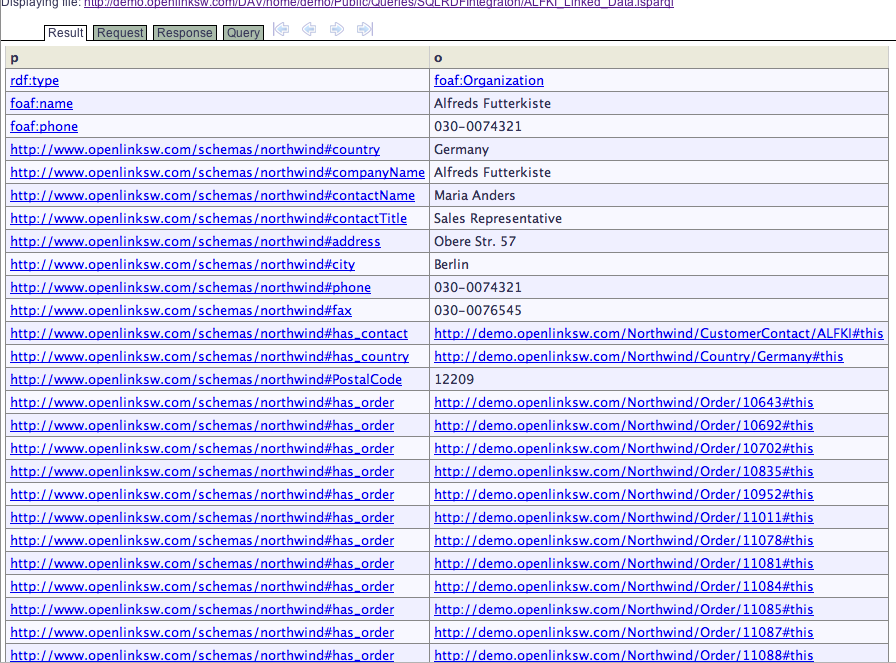
Northwind URL Rewriting Verification Using curl
As illustrated earlier, the curl utility provides a useful tool for verifying HTTP server responses and rewriting rules.
The curl exchanges below show the URL rewriting rules defined for the Northwind Linked Data View being applied.
Example 1
$ curl -I -H "Accept: text/html" http://demo.openlinksw.com/Northwind/Customer/ALFKI
HTTP/1.1 303 See Other
Server: Virtuoso/05.00.3016 (Solaris) x86_64-sun-solaris2.10-64 PHP5
Connection: close
Content-Type: text/html; charset=ISO-8859-1
Date: Tue, 14 Aug 2007 13:30:02 GMT
Accept-Ranges: bytes
Location: /isparql/execute.html?query=SELECT%20%3Fp%20%3Fo%20FROM%20%3Chttp%3A//dem
o.openlinksw.com/Northwind%3E%20WHERE%20{%20%3Chttp%3A//demo.openlinksw.com/Northwin
d/Customer/ALFKI%23this%3E%20%3Fp%20%3Fo%20}&endpoint=/sparql
Content-Length: 0
Example 2
$ curl -I -H "Accept: application/rdf+xml" http://demo.openlinksw.com/Northwind/Cust
omer/ALFKI
HTTP/1.1 303 See Other
Server: Virtuoso/05.00.3016 (Solaris) x86_64-sun-solaris2.10-64 PHP5
Connection: close
Content-Type: text/html; charset=ISO-8859-1
Date: Tue, 14 Aug 2007 13:30:22 GMT
Accept-Ranges: bytes
Location: /sparql?query=CONSTRUCT+{+%3Chttp%3A//demo.openlinksw.com/Northwind/Custom
er/ALFKI%23this%3E+%3Fp+%3Fo+}+FROM+%3Chttp%3A//demo.openlinksw.com/Northwind%3E+WHE
RE+{+%3Chttp%3A//demo.openlinksw.com/Northwind/Customer/ALFKI%23this%3E+%3Fp+%3Fo+}&
format=application/rdf%2Bxml
Content-Length: 0
Example 3
$ curl -I -H "Accept: text/html" http://demo.openlinksw.com/Northwind/Customer/ALFKI #this HTTP/1.1 404 Not Found Server: Virtuoso/05.00.3016 (Solaris) x86_64-sun-solaris2.10-64 PHP5 Connection: Keep-Alive Content-Type: text/html; charset=ISO-8859-1 Date: Tue, 14 Aug 2007 13:31:01 GMT Accept-Ranges: bytes Content-Length: 0
The output above shows how RDF entities from the Data-Web, in this case customer ALFKI, are exposed in the Document Web.
The power of SPARQL coupled with URL rewriting enables us to produce results in line with the desired representation.
A SPARQL SELECT or CONSTRUCT query is used depending on whether the requested representation is text/html or application/rdf+xml, respectively.
The 404 response in Example 3 indicates that no HTML representation is available for entity ALFKI#this.
In most cases, a URI of this form (containing a '#' fragment identifier) will not reach the server.
This example supposes that it does, i.e., the RDF client and network routing allows the suffixed request.
The presence of the #this suffix implicitly states
that this is a request for a data resource in the Data-Web realm, not a document resource from the Document Web.
Note 2
Rather than return 404, we could instead choose to construct our rewriting rules to perform a 303 redirect, so that the response for ALFKI#this in Example 3 becomes the same as that for ALFKI in Example 1.
Transparent Content Negotiation
So as not to overload our preceding description of Linked Data deployment with excessive detail, the description of content negotiation presented thus far was kept deliberately brief. This section discusses content negotiation in more detail.
HTTP/1.1 Content Negotiation
Recall that a resource (conceptual entity) identified by a URI may be associated with more than one representation (e.g., multiple languages, data formats, sizes, resolutions).
If multiple representations are available, the resource is referred to as negotiable and each of its representations is termed a variant.
For instance, a Web document resource, named 'ALFKI' may have three variants: alfki.xml, alfki.html, and alfki.txt, all representing the same data.
Content negotiation provides a mechanism for selecting the best variant.
As outlined in the earlier brief discussion of content negotiation, when a user agent requests a resource, it can include with the request Accept headers (Accept, Accept-Language, Accept-Charset, Accept-Encoding, etc.) which express the user preferences and user agent capabilities.
The server then chooses and returns the best variant based on the Accept headers.
Because the selection of the best resource representation is made by the server, this scheme is classed as server-driven negotiation.
Transparent Content Negotiation
An alternative content negotiation mechanism is Transparent Content Negotiation (TCN), a protocol defined by RFC2295. TCN offers a number of benefits over standard HTTP/1.1 negotiation, for suitably enabled user agents.
RFC2295 introduces a number of new HTTP headers including the Negotiate request header, and the TCN and Alternates response headers.
(Krishnamurthy et al note that although the HTTP/1.1 specification reserved the Alternates header for use in agent- driven negotiation, it was not fully specified.
Consequently under a pure HTTP/1.1 implementation as defined by RFC2616, server-driven content negotiation is the only option.
RFC2295 addresses this issue.)
Deficiencies of HTTP/1.1 Server-Driven Negotiation
Weaknesses of server-driven negotiation highlighted by RFCs 2295 and 2616 include:
- Inefficiency — Sending details of a user agent's capabilities and preferences with every request is very inefficient, not least because very few Web resources have multiple variants, and expensive in terms of the number of
Acceptheaders required to fully describe all but the most simple browser's capabilities. - Server doesn't always know 'best' — Having the server decide on the 'best' variant may not always result in the most suitable resource representation being returned to the client. The user agent might often be better placed to decide what is best for its needs.
Variant Selection By User Agent
Rather than rely on server-driven negotiation and variant selection by the server, a user agent can take full control over deciding the best variant by explicitly requesting transparent content negotiation through the Negotiate request header.
The negotiation is 'transparent' because it makes all the variants on the server visible to the agent.
Under this scheme, the server sends the user agent a list, represented in an Alternates header, containing the available variants and their properties.
The user agent can then choose the best variant itself.
Consequently, the agent no longer needs to send large Accept headers describing in detail its capabilities and preferences.
(However, unless caching is used, user-agent driven negotiation does suffer from the disadvantage of needing a second request to obtain the best representation.
By sending its best guess as the first response, server driven negotiation avoids this second request if the initial best guess is acceptable.)
Variant Selection By Server
As well as variant selection by the user agent, TCN allows the server to choose on behalf of the user agent if the user agent explicitly allows it through the Negotiate request header.
This option allows the user agent to send smaller Accept headers containing enough information to allow the server to choose the best variant and return it directly.
The server's choice is controlled by a 'remote variant selection algorithm' as defined in RFC2296.
Variant Selection By End-User
A further option is to allow the end-user to select a variant, in case the choice made by negotiation process is not optimal. For instance, the user agent could display an HTML-based 'pick list' of variants constructed from the variant list returned by the server. Alternatively the server could generate this pick list itself and include it in the response to a user agent's request for a variant list. (Virtuoso currently responds this way.)
Transparent Content Negotiation in Virtuoso HTTP Server
The following section describes the Virtuoso HTTP server's TCN implementation which is based on RFC2295, but without "Feature" negotiation.
OpenLink's RDF rich clients, iSparql and the OpenLink RDF Browser, both support TCN.
User agents which do not support transparent content negotiation continue to be handled using HTTP/1.1 style content negotiation (whereby server-side selection is the only option - the server selects the best variant and returns a list of variants in an Alternates response header).
Describing Resource Variants
In order to negotiate a resource, the server needs to be given information about each of the variants.
Variant descriptions are held in SQL table HTTP_VARIANT_MAP.
The descriptions themselves can be created, updated or deleted using Virtuoso/PL or through the Conductor UI.
HTTP_VARIANT_MAP Table Definition
The table definition is as follows:
create table DB.DBA.HTTP_VARIANT_MAP ( VM_ID integer identity, -- unique ID VM_RULELIST varchar, -- HTTP rule list name VM_URI varchar, -- name of requested resource e.g. 'page' VM_VARIANT_URI varchar, -- name of variant e.g. 'page.xml', 'page.de.html' etc. VM_QS float, -- Source quality, a number in the range 0.001-1.000, with 3 digit precision VM_TYPE varchar, -- Content type of the variant e.g. text/xml VM_LANG varchar, -- Content language e.g. 'en', 'de' etc. VM_ENC varchar, -- Content encoding e.g. 'utf-8', 'ISO-8892' etc. VM_DESCRIPTION long varchar, -- a human readable description about the variant e.g. 'Profile in RDF format' VM_ALGO int default 0, -- reserved for future use primary key (VM_RULELIST, VM_URI, VM_VARIANT_URI) ) create unique index HTTP_VARIANT_MAP_ID on DB.DBA.HTTP_VARIANT_MAP (VM_ID)
Configuration using Virtuoso/PL
Two functions are provided for adding or updating, or removing variant descriptions using Virtuoso/PL:
Adding or Updating a Resource Variant:
DB.DBA.HTTP_VARIANT_ADD ( in rulelist_uri varchar, -- HTTP rule list name in uri varchar, -- Requested resource name e.g. 'page' in variant_uri varchar, -- Variant name e.g. 'page.xml', 'page.de.html' etc. in mime varchar, -- Content type of the variant e.g. text/xml in qs float := 1.0, -- Source quality, a floating point number with 3 digit precision in 0.001-1.000 range in description varchar := null, -- a human readable description of the variant e.g. 'Profile in RDF format' in lang varchar := null, -- Content language e.g. 'en', 'bg'. 'de' etc. in enc varchar := null -- Content encoding e.g. 'utf-8', 'ISO-8892' etc. )
Removing a Resource Variant
DB.DBA.HTTP_VARIANT_REMOVE ( in rulelist_uri varchar, -- HTTP rule list name in uri varchar, -- Name of requested resource e.g. 'page' in variant_uri varchar := '%' -- Variant name filter )
Configuration using Conductor UI
The Conductor 'Content negotiation' panel for describing resource variants and configuring content negotiation is depicted below.
It can be reached by selecting the 'HTTP Hosts & Directories' tab under the 'WebDAV & HTTP' menu item, then selecting the 'URL rewrite' option for a logical path listed amongst those for the relevant HTTP host, e.g., '{Default Web Site}'.
The screen snapshot shows the variant descriptions created by issuing the HTTP_VARIANT_ADD and VHOST_DEFINE Virtuoso/PL calls detailed in the examples at the end of this section.
Obviously these definitions could instead have been created entirely 'from scratch' through the Conductor UI.
The input fields reflect the supported 'dimensions' of negotiation which include content type, language and encoding. Quality values corresponding to the options for 'Source Quality' are as follows:
| Source Quality | Quality Value |
|---|---|
| perfect representation | 1.000 |
| threshold of noticeable loss of quality | 0.900 |
| noticeable, but acceptable quality reduction | 0.800 |
| barely acceptable quality | 0.500 |
| severely degraded quality | 0.300 |
| completely degraded quality | 0.000 |
Variant Selection Algorithm
When a user agent instructs the server to select the best variant, Virtuoso does so using the selection algorithm below:
If a virtual directory has URL rewriting enabled (has the 'url_rewrite' option set), the web server:
- Looks in
DB.DBA.HTTP_VARIANT_MAPfor aVM_RULELISTmatching the one specified in the 'url_rewrite' option
- If present, it loops over all variants for which
VM_URIis equal to the resource requested
- For every variant it calculates the source quality based on the value of
VM_QSand the source quality given by the user agent
- If the best variant is found, it adds TCN HTTP headers to the response and passes the
VM_VARIANT_URIto the URL rewriter
- If the user agent has asked for a variant list, it composes such a list and returns an '
Alternates' HTTP header with response code300
- If no URL rewriter rules exist for the target URL, the web server returns the content of the dereferenced
VM_VARIANT_URI.
The server may return the best-choice resource representation or a list of available resource variants.
When a user agent requests transparent negotiation, the web server returns the TCN header "choice".
When a user agent asks for a variant list, the server returns the TCN header "list".
Examples
In this example we assume the following files have been uploaded to the Virtuoso WebDAV server, with each containing the same information but in different formats:
/DAV/TCN/page.xml- a XML variant/DAV/TCN/page.html- a HTML variant/DAV/TCN/page.txt- a text variant
We add TCN rules and define a virtual directory:
DB.DBA.HTTP_VARIANT_ADD ('http_rule_list_1', 'page', 'page.html', 'text/html',
0.900000, 'HTML variant'); DB.DBA.HTTP_VARIANT_ADD ('http_rule_list_1', 'page',
'page.txt', 'text/plain', 0.500000, 'Text document'); DB.DBA.HTTP_VARIANT_ADD
('http_rule_list_1', 'page', 'page.xml', 'text/xml', 1.000000, 'XML variant');
DB.DBA.VHOST_DEFINE (lpath=>'/DAV/TCN/', ppath=>'/DAV/TCN/', is_dav=>1,
vsp_user=>'dba', opts=>vector ('url_rewrite', 'http_rule_list_1'));
Having done this we can now test the setup with a suitable HTTP client, in this case the curl command line utility.
In the following examples, the curl client supplies Negotiate request headers containing content negotiation directives which include:
- "
trans" — The user agent supports transparent content negotiation for the current request. - "
vlist" — The user agent requests that any transparently negotiated response for the current request includes an Alternates header with the variant list bound to the negotiable resource. Implies "trans". - "
*" — The user agent allows servers and proxies to run any remote variant selection algorithm.
The server returns a TCN response header signaling that the resource is transparently negotiated and either a choice or a list response as appropriate.
In the first curl exchange, the user agent indicates to the server that, of the formats it recognizes, HTML is preferred and it instructs the server to perform transparent content negotiation.
In the response, the Vary header field expresses the parameters the server used to select a representation, i.e., only the Negotiate and Accept header fields are considered.
$ curl -i -H "Accept: text/xml;q=0.3,text/html;q=1.0,text/plain;q=0.5,*/*;q=0.3" -H "Negotiate: *" http://localhost:8890/DAV/TCN/page HTTP/1.1 200 OK Server: Virtuoso/05.00.3021 (Linux) i686-pc-linux-gnu VDB Connection: Keep-Alive Date: Wed, 31 Oct 2007 15:43:18 GMT Accept-Ranges: bytes TCN: choice Vary: negotiate,accept Content-Location: page.html Content-Type: text/html ETag: "14056a25c066a6e0a6e65889754a0602" Content-Length: 49 <html> <body> some html </body> </html>
Next, the source quality values are adjusted so that the user agent indicates that XML is its preferred format.
$ curl -i -H "Accept: text/xml,text/html;q=0.7,text/plain;q=0.5,*/*;q=0.3" -H "Negot iate: *" http://localhost:8890/DAV/TCN/page HTTP/1.1 200 OK Server: Virtuoso/05.00.3021 (Linux) i686-pc-linux-gnu VDB Connection: Keep-Alive Date: Wed, 31 Oct 2007 15:44:07 GMT Accept-Ranges: bytes TCN: choice Vary: negotiate,accept Content-Location: page.xml Content-Type: text/xml ETag: "8b09f4b8e358fcb7fd1f0f8fa918973a" Content-Length: 39 <?xml version="1.0" ?> <a>some xml</a>
In the final example, the user agent wants to decide itself which is the most suitable representation, so it asks for a list of variants.
The server provides the list, in the form of an Alternates response header, and, in addition, sends an HTML representation of the list so that the end user can decide on the preferred variant himself if the user agent is unable to.
$ curl -i -H "Accept: text/xml,text/html;q=0.7,text/plain;q=0.5,*/*;q=0.3" -H "Negot
iate: vlist" http://localhost:8890/DAV/TCN/page
HTTP/1.1 300 Multiple Choices
Server: Virtuoso/05.00.3021 (Linux) i686-pc-linux-gnu VDB
Connection: close
Content-Type: text/html; charset=ISO-8859-1
Date: Wed, 31 Oct 2007 15:44:35 GMT
Accept-Ranges: bytes
TCN: list
Vary: negotiate,accept
Alternates: {"page.html" 0.900000 {type text/html}}, {"page.txt" 0.500000 {type text
/plain}}, {"page.xml" 1.000000 {type text/xml}}
Content-Length: 368
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html>
<head>
<title>300 Multiple Choices</title>
</head>
<body>
<h1>Multiple Choices</h1>
Available variants:
<ul>
<li>
<a href="page.html">HTML variant</a>, type text/html</li>
<li><a href="page.txt">Text document</a>, type text/plain</li>
<li><a href="page.xml">XML variant</a>, type text/xml</li>
</ul>
</body>
</html>
Glossary
- class: A concept in a domain of interest. A class describes the common attributes and behaviors shared by entities belonging to the same group by virtue of their common characteristics.
- content negotiation: A mechanism defined in HTTP which supports serving different representations of a URL-addressable resource. An HTTP client can indicate which representation formats it understands and prefers.
cURL: A command line tool for transferring files to or from a URL. It writes to standard output by default and provides a good tool for simulating a web browser's interaction with an HTTP server.- data resource: same as data source
- data source: A source of data (e.g., a place that provides access to property values associated with one or more Entities).
- data space: A moniker for Web-accessible atomic containers that manage and expose data, information, services, processes, and knowledge. Data Spaces are fundamentally problem-domain-specific database applications with the benefit of being data model and query language agnostic.
- dereferencing: The act of accessing and retrieving data, in desired representation, from a location identified by URL.
- document resource: A Web information resource in a specific representation that is identifiable and accessible via a URL. Documents are the dominant information resource form on the Document Web (i.e., the current Web).
- Document Web: Web of Linked Documents.
- entity: Something, real or conceptual, which exists apart from other things.
- entity ID: A unique identifier for an entity, uniquely identifying and distinguishing a particular entity instance from other similar entities (typically of the same type or class).
- entity set: A collection of entities all belonging to the same class.
- HTTP: Hypertext Transport Protocol.
- HTTP header: A text record exchanged between an HTTP client and server, which forms part of an HTTP request or HTTP response message. A request consists of a method (or verb), headers, and an optional message body. The request header fields allow the client to send additional information about the request and the client itself. A response consists of a status line, headers, and an optional message body. A response header typically contains information about the data being returned and about the server itself.
- Hypertext Transport Protocol): A communication protocol for information transfer on the World Wide Web.
- information resource: An encapsulation of data and representation that forms the basic payload unit (packet) on the Web Information Bus.
- IRI (Internationalized Resource Identifier): An internationalized version of a Uniform Resource Identifier (URI). While URIs are limited to a subset of the ASCII character set, IRIs may contain any Unicode character.
- Linked Data: Information resource(s) encapsulating Structured Data expressed in RDF.
- non-information resource: Any resource that is not an information resource (i.e., not Web transportable in basic form). Structured data resource (see below) is a more accurate and preferable term.
- Semantic Data-Web: Web of Linked Data.
- structured data: Data organized into semantic chunks or entities, with similar entities grouped together in relations or classes, and presented in a patterned manner.
- structured data resource: A Web accessible container of structured data representing physical and abstract entities.
- structured data source: A repository of structured data.
- URI (Uniform Resource Identifier ): An Internet naming syntax which identifies a resource. The resource may be abstract and consequently not dereferenceable.
- URL (Uniform Resource Locator): An Internet naming syntax, which specifies both the identity and location of a physical, dereferenceable Web information resource. Although URLs and URIs share the same syntax, a URI specifies only the identity of a resource.
- Web information resource: An entity of interest, which both exists in some form and is accessible on the World Wide Web.
Notes
- Reiterating our earlier point, the URL identifies the resource, not its representations. return
- Some Semantic Web (SemWeb) practitioners have argued in favor of using the URI format to distinguish between requests for document resources (also sometimes termed as information resources) belonging to the Document Web, and Data Sources, i.e., physical or abstract RDF entities (also sometimes referred to as non-information resources) belonging to the Data Web. (The terms information resource and non-information resource are disliked by many and have generated a good deal of debate.) With this so-called 'hash vs. slash' URI convention, the presence of a fragment identifier (a hash URI, using the "#") is taken to mean that a data source (entity) is being referenced; the absence of a fragment identifier (a slash URI, not using the "#") implies a document resource is being referenced. return
Bibliography
- OpenLink Software: Virtuoso Linked Data Views - Getting Started Guide
- T. Berners-Lee: Linked Data
- C. Bizer et al.: How to Publish Linked Data on the Web
- L. Sauermann et al.: Cool URIs for the Semantic Web
- P. Hayes: In Defence of Ambiguity
- R. Cyganiak: Debugging Semantic Web Sites With cURL
- W3C: Dereferencing HTTP URIs
- W3C: What do HTTP URIs Identify?
- W3C: What URIs Identify
- W3C: [httpRange-14] Resolved
- W3C: Best Practice Recipes for Publishing RDF Vocabularies
- Wikipedia: Using HTTP URIs to identify abstract resources
- B. Krishnamurthy et al.: Key Differences between HTTP/1.0 and HTTP/1.1
- R. Fielding et al.: RFC2616 - HyperText Transfer Protocol - HTTP/1.1
- K. Holtman & A. Mutz: RFC2295 - Transparent Content Negotiation in HTTP
See Also
Change History
1.0 Initial draft (K. Idehen / C. Blakeley, 14 Aug 2007)
1.1 Additions covering transparent content negotiation (C. Blakeley, 07 Nov 2007)
1.2 ???
1.3 Edit and polish (T. Thibodeau, K. Idehen, etc., Nov 2008)