Virtuoso Bulk Load Example: DBpedia data sets
The following example demonstrates how to upload the DBpedia data sets into Virtuoso using the Bulk Loading Sequence.
- Assuming there is a folder named "
tmp" in your filesystem, and it is within a directory specified in theDirsAllowedparam defined in yourvirtuoso.inifile. - Load the required DBpedia data sets into the "
tmp" folder- The latest data sets can be downloaded from the DBpedia Download page.
Note the compressed bzip'ed "
.bz2" data set files need to be uncompressed first as the bulk loader scripts only supports the auto extraction of gzip'ed ".gz" files.
- The latest data sets can be downloaded from the DBpedia Download page.
Note the compressed bzip'ed "
- If it hasn't already been, execute the Bulk Loading script.
- Register the graph IRI under which the triples are to be loaded, e.g., "
http://dbpedia.org":
SQL> ld_dir ('tmp', '*.*', 'http://dbpedia.org'); Done. -- 90 msec.- Note that while this procedure will also work with gzip'ed files, it is important to keep the pattern:
<name>.<ext>.gz, e.g., 'ontology.owl.gz' orontology.nt.gz - Note that if there are other data files in your folder (
tmp), then their content will also be loaded into the specified graph.
- Note that while this procedure will also work with gzip'ed files, it is important to keep the pattern:
- Create a file named
global.graphin the "tmp" folder, with its entire content being the URI of the desired target graph, e.g.,
http://dbpedia.org - Finally, execute the
rdf_loader_runprocedure. This may take some time, depending on the size of the data sets.
SQL> rdf_loader_run (); Done. -- 100 msec. - As a result, the Virtuoso log should contain notification that the loading has completed:
10:21:50 PL LOG: Loader started 10:21:50 PL LOG: No more files to load. Loader has finished - Run a
checkpointto commit all transactions to the database.
SQL> checkpoint; Done. -- 53 msec. - To check the inserted triples for the given graph, execute a query similar to --
SQL> SPARQL SELECT COUNT(*) FROM <http://dbpedia.org> WHERE { ?s ?p ?o } ; - Install the DBpedia and RDF Mappers VAD packages, using either the Virtuoso Conductor or the following manual commands:
SQL> vad_install ('dbpedia_dav.vad', 0); SQL> vad_install ('rdf_mappers_dav.vad', 0); - The Virtuoso-hosted data set can now be explored using a HTML browser, or queried from the SPARQL or Faceted Browser web service endpoints.
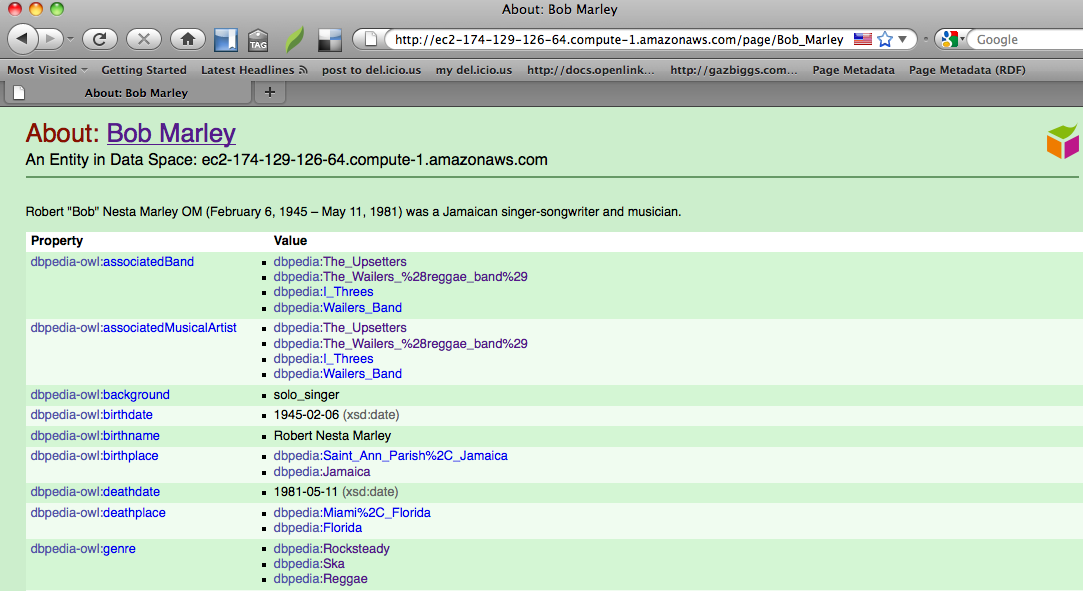
For example, with the DBpedia 3.5.1 data sets, a description of the resource Bob Marley can be viewed as:
http://<your-cname>:<your-port>/resource/Bob_Marley