Setting up a Content Crawler Job to Retrieve Content from SPARQL endpoint
The following step-by guide walks you through the process of:
- Populating a Virtuoso Quad Store with data from a 3rd party SPARQL endpoint
- Generating RDF dumps that are accessible to basic HTTP or WebDAV user agents.
- Sample SPARQL query producing a list SPARQL endpoints:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX owl: <http://www.w3.org/2002/07/owl#> PREFIX xsd: <http://www.w3.org/2001/XMLSchema#> PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX dcterms: <http://purl.org/dc/terms/> PREFIX scovo: <http://purl.org/NET/scovo#> PREFIX void: <http://rdfs.org/ns/void#> PREFIX akt: <http://www.aktors.org/ontology/portal#> SELECT DISTINCT ?endpoint WHERE { ?ds a void:Dataset . ?ds void:sparqlEndpoint ?endpoint }
- Here is a sample SPARQL protocol URL constructed from one of the sparql endpoints in the result from the query above:
http://void.rkbexplorer.com/sparql/?query=PREFIX+foaf%3A+%3Chttp%3A%2F%2Fxmlns.com%2Ffoaf%2F0.1%2F%3E+%0D%0APREFIX+void%3A+++++%3Chttp%3A%2F%2Frdfs.org%2Fns%2Fvoid%23%3E++%0D%0ASELECT+distinct+%3Furl++WHERE+%7B+%3Fds+a+void%3ADataset+%3B+foaf%3Ahomepage+%3Furl+%7D%0D%0A&format=sparql
- Here is the cURL output showing a Virtuoso SPARQL URL that executes against a 3rd party SPARQL Endpoint URL:
$ curl "http://void.rkbexplorer.com/sparql/?query=PREFIX+foaf%3A+%3Chttp%3A%2F%2Fxmlns.com%2Ffoaf%2F0.1%2F%3E+%0D%0APREFIX+void %3A+++++%3Chttp%3A%2F%2Frdfs.org%2Fns%2Fvoid%23%3E++%0D%0ASELECT+distinct+%3Furl++WHERE+%7B+%3Fds+a+void%3ADataset+%3B+foaf%3Ah omepage+%3Furl+%7D%0D%0A&format=sparql" <?xml version="1.0"?> <sparql xmlns="http://www.w3.org/2005/sparql-results#"> <head> <variable name="url"/> </head> <results ordered="false" distinct="true"> <result> <binding name="url"><uri>http://kisti.rkbexplorer.com/</uri></binding> </result> <result> <binding name="url"><uri>http://epsrc.rkbexplorer.com/</uri></binding> </result> <result> <binding name="url"><uri>http://test2.rkbexplorer.com/</uri></binding> </result> <result> <binding name="url"><uri>http://test.rkbexplorer.com/</uri></binding> </result> ... ... ... </results> </sparql>
- Go to Conductor UI.
For ex.
http://localhost:8890/conductor :
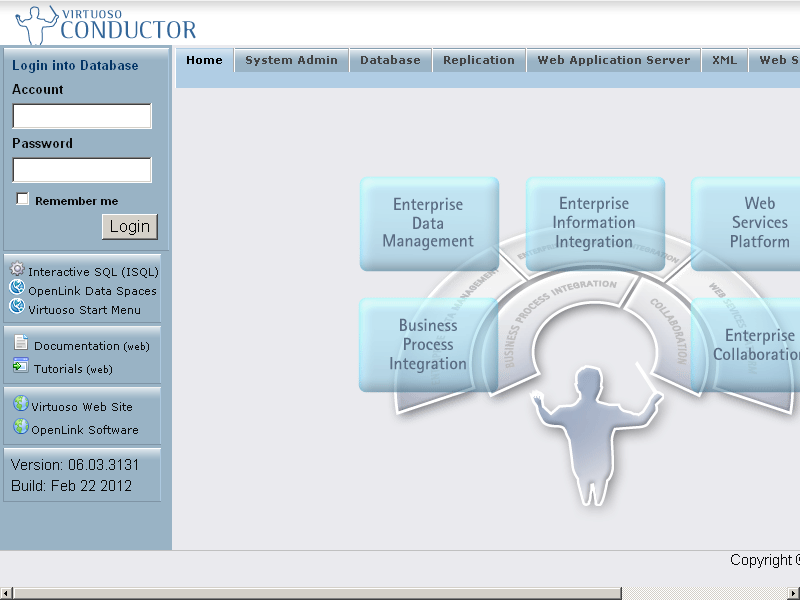
- Enter dba credentials
- Go to "Web Application Server"-> "Content Management" -> "Content Imports"
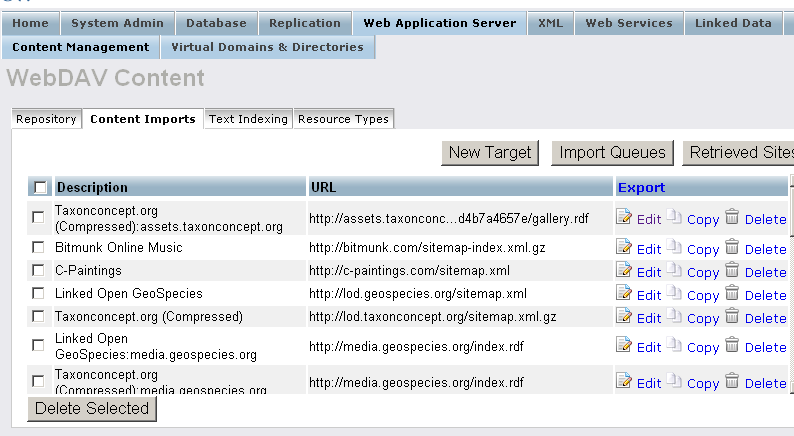
- Click "New Target"
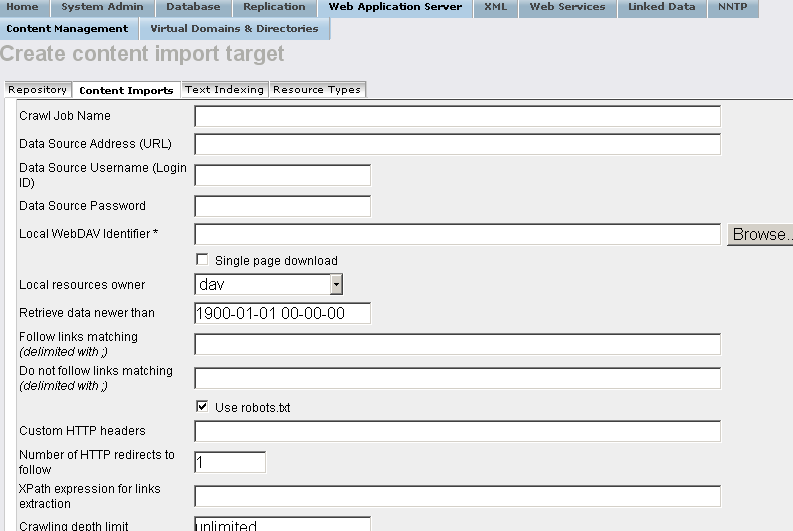
- In the presented form enter for ex.:
- "Crawl Job Name": voiD store
- "Data Source Address (URL)": the url from above i.e.:
http://void.rkbexplorer.com/sparql/?query=PREFIX+foaf%3A+%3Chttp%3A%2F%2Fxmlns.com%2Ffoaf%2F0.1%2F%3E+%0D%0APREFIX+void%3A+++++%3Chttp%3A%2F%2Frdfs.org%2Fns%2Fvoid%23%3E++%0D%0ASELECT+distinct+%3Furl++WHERE+%7B+%3Fds+a+void%3ADataset+%3B+foaf%3Ahomepage+%3Furl+%7D%0D%0A&format=sparql
- "Local WebDAV Identifier":
/DAV/void.rkbexplorer.com/content
- "Follow links matching (delimited with ;)":
%
- Un-hatch "Use robots.txt" ;
- "XPath expression for links extraction":
//binding[@name="url"]/uri/text()
- Hatch "Semantic Web Crawling";
- "If Graph IRI is unassigned use this Data Source URL:": enter for ex:
http://void.collection
- Hatch "Follow URLs outside of the target host";
- Hatch "Run "Sponger" and "Accept RDF"
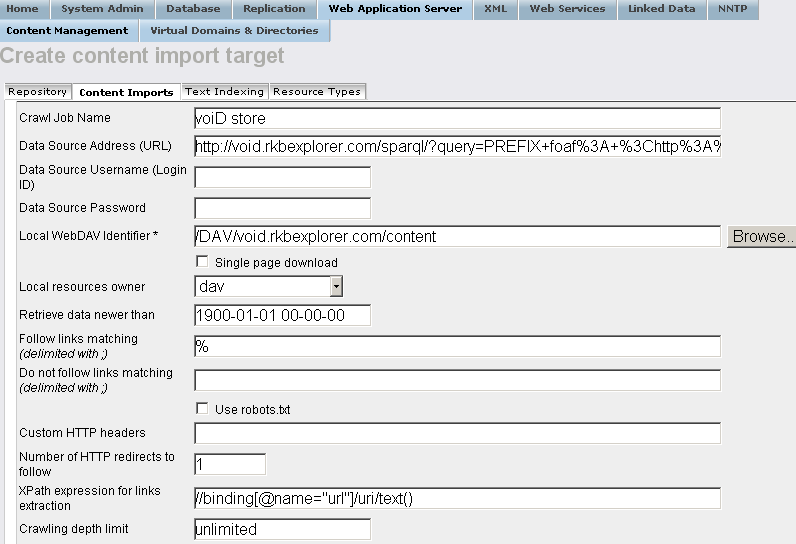
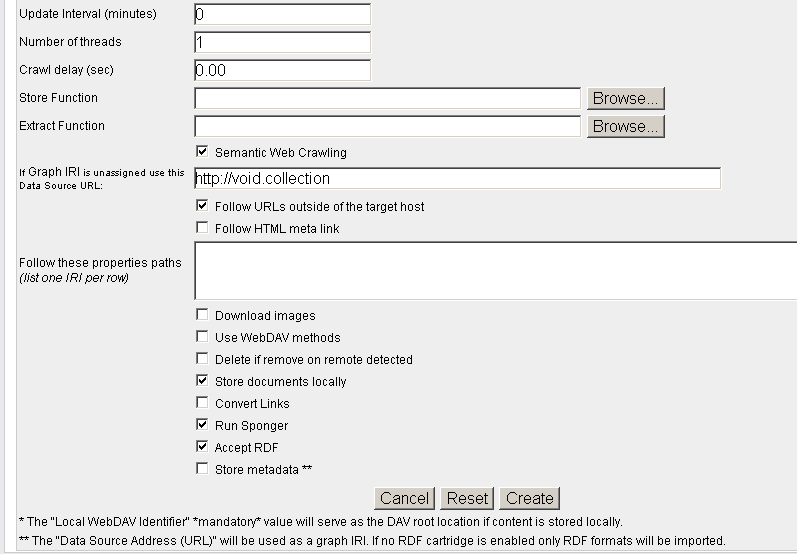
- Click "Create".
- The target should be created and presented in the list of available targets:
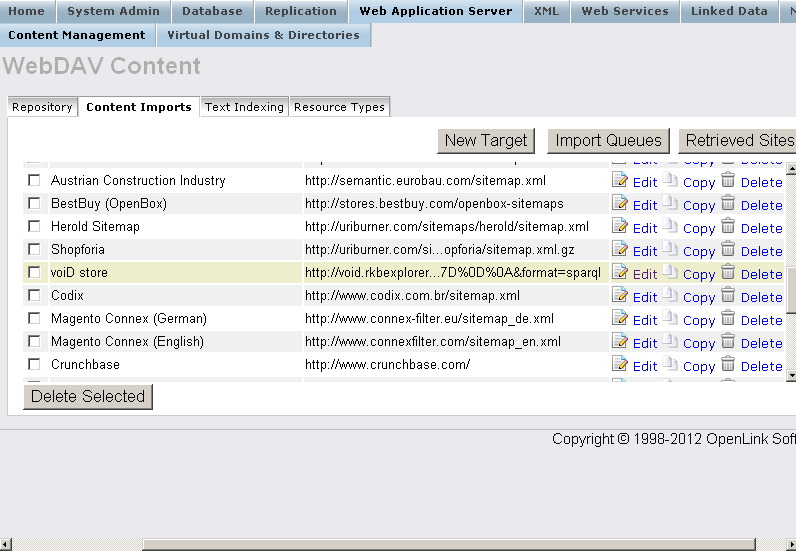
- Click "Import Queues":
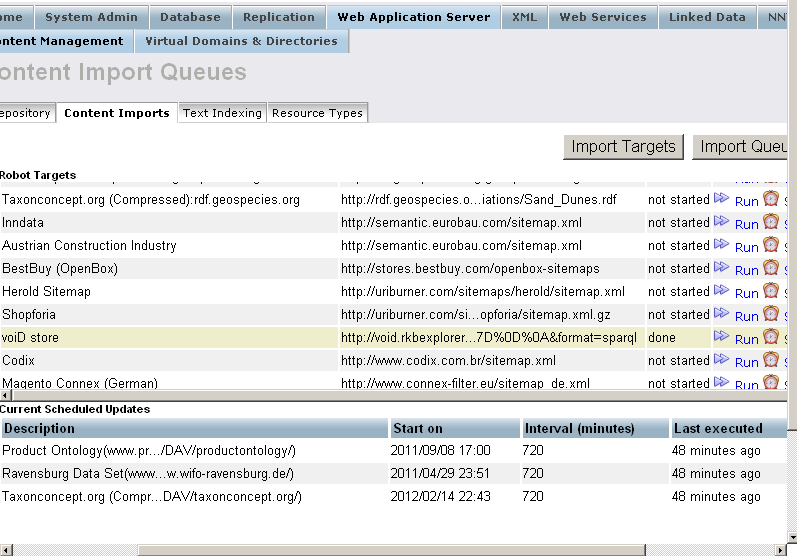
- Click "Run" for the imported target:
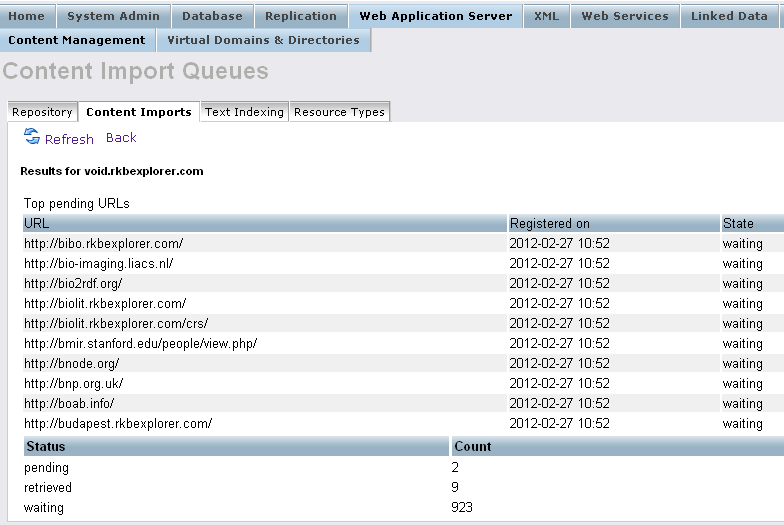
- To check the retrieved content go to "Web Application Server"-> "Content Management" -> "Content Imports" -> "Retrieved Sites":
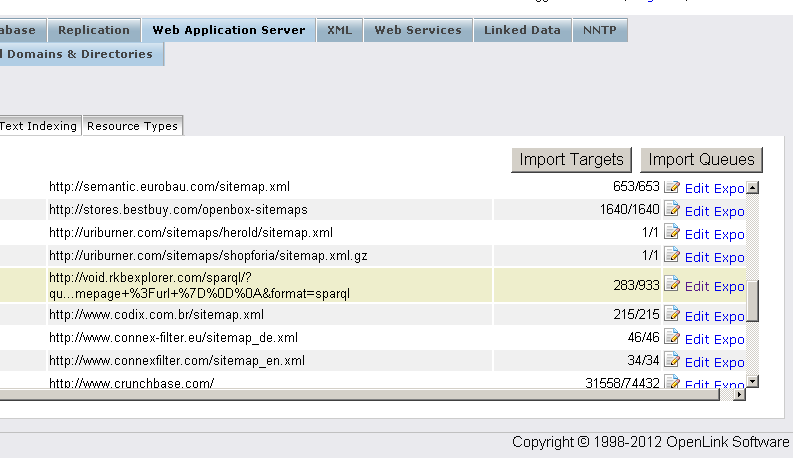
- Click voiD store -> "Edit":
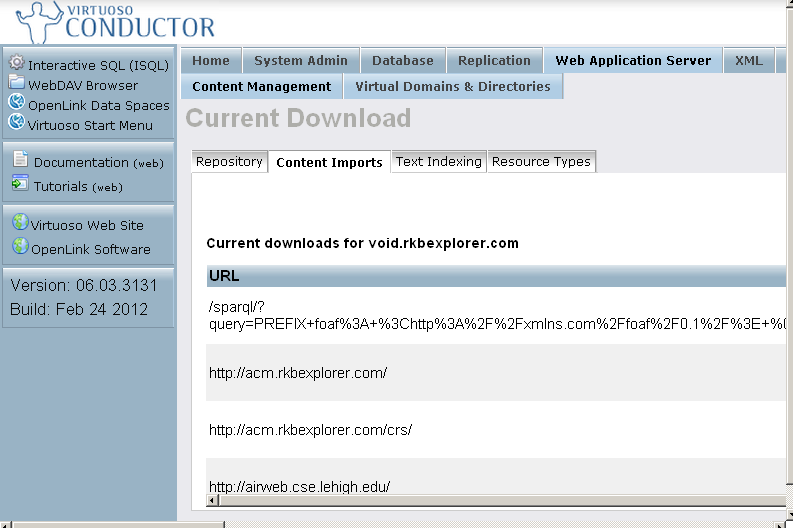
- To check the imported URLs go to "Web Application Server"-> "Content Management" -> "Repository" path DAV/void.rkbexplorer.com/content:

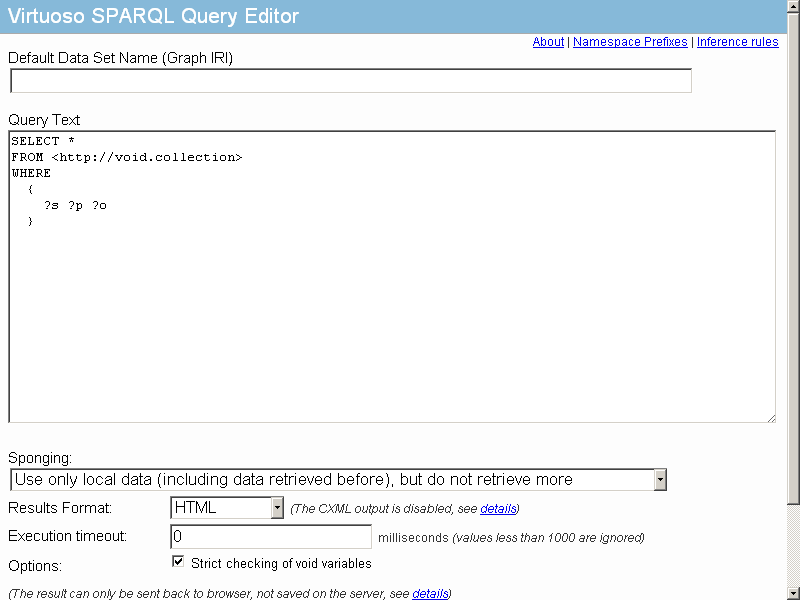
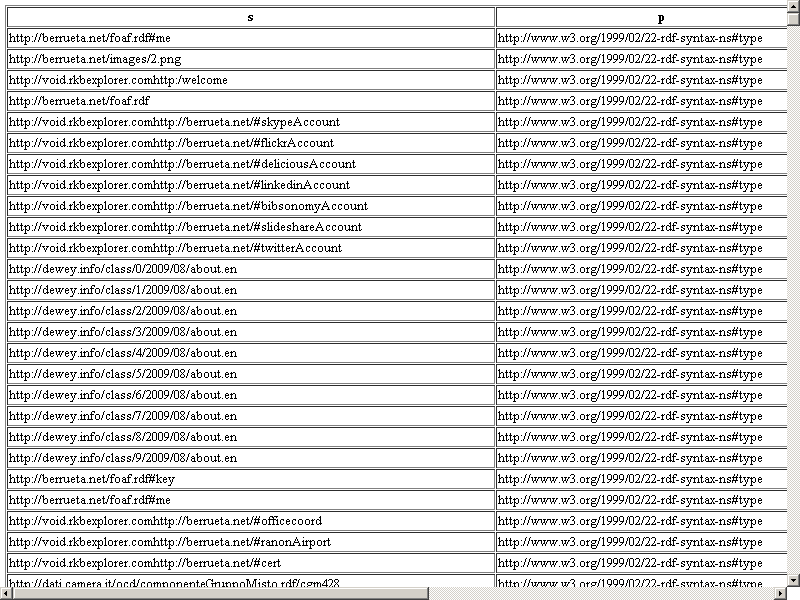
- To check the inserted into the RDF QUAD data go to http://cname/sparql and execute the following query:
SELECT * FROM <http://void.collection> WHERE { ?s ?p ?o }
Related
- Setting up a Content Crawler Job to Add RDF Data to the Quad Store
- Setting up a Content Crawler Job to Retrieve Sitemaps (when the source includes RDFa)
- Setting up a Content Crawler Job to Retrieve Semantic Sitemaps (a variation of the standard sitemap)
- Setting up a Content Crawler Job to Retrieve Content from Specific Directories
- Setting up a Content Crawler Job to Retrieve Content from ATOM feed