
Setting up a Content Crawler Job to Retrieve Content from Specific Directories
The following guide describes how to set up crawler job for getting directories using Conductor.
- Go to Conductor UI. For ex. at http://localhost:8890/conductor .
- Enter dba credentials.
- Go to "Web Application Server".
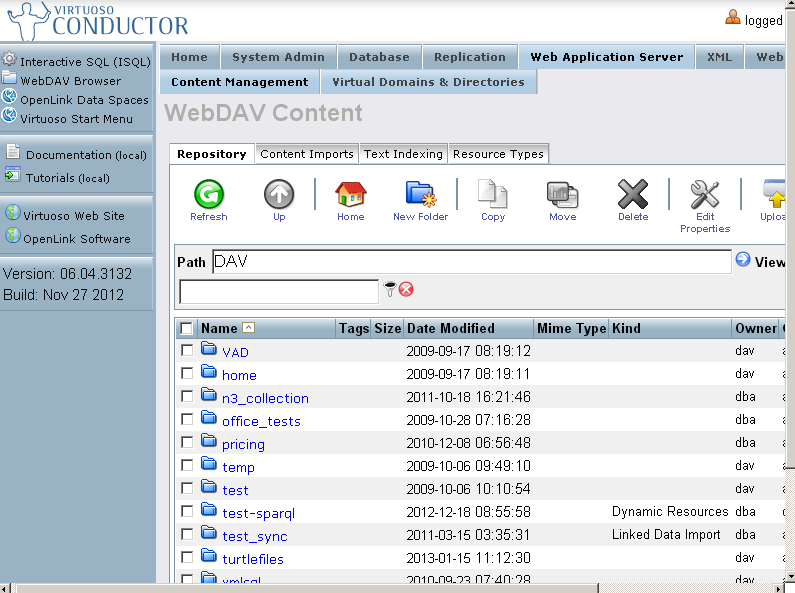
- Go to "Content Imports".
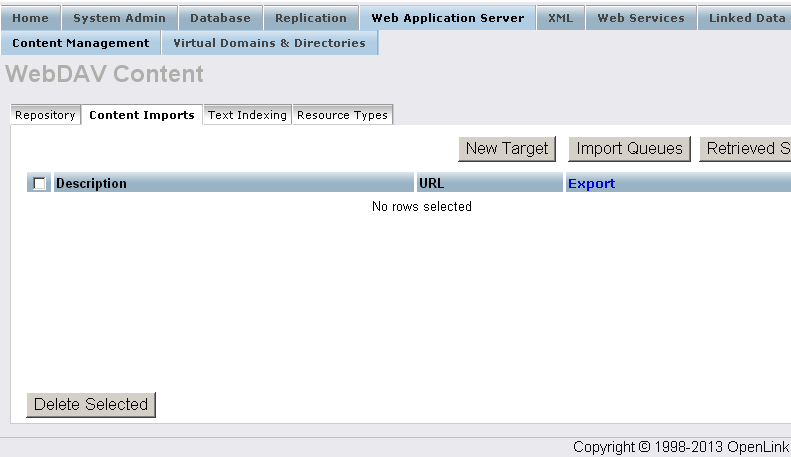
- Click "New Target".
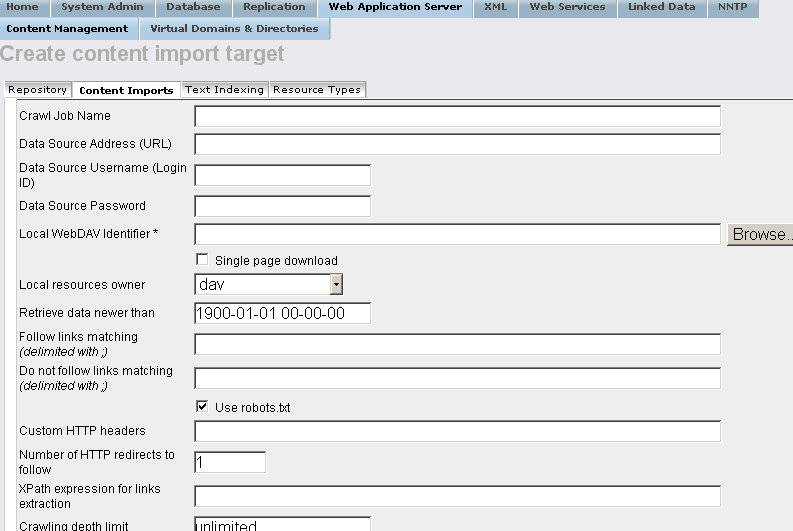
- In the shown form set respectively:
- "Crawl Job Name":
Gov.UK data
- "Data Source Address (URL)":
http://source.data.gov.uk/data/
- "Local WebDAV Identifier" for available user, for ex.
demo:
/DAV/home/demo/gov.uk/
- Choose from the available list "Local resources owner" an user, for ex.
demo ;
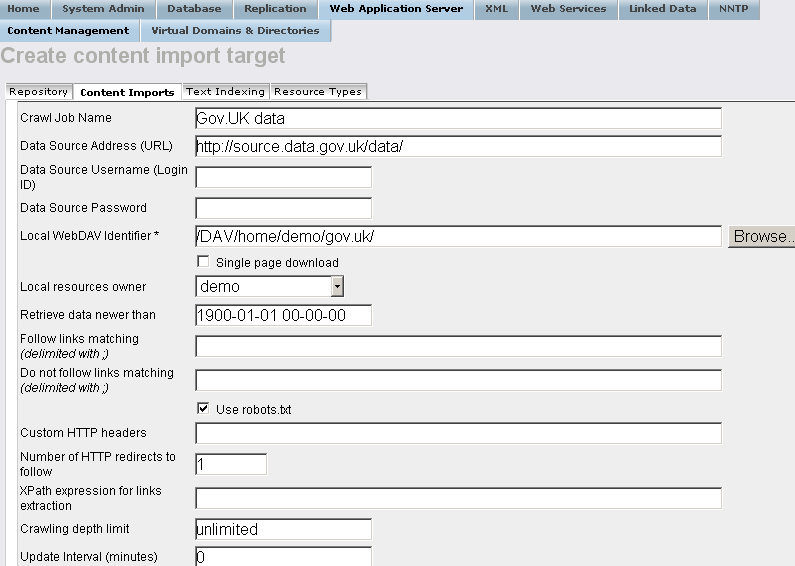
- Click the button "Create".
- "Crawl Job Name":
- As result the Robot target will be created:
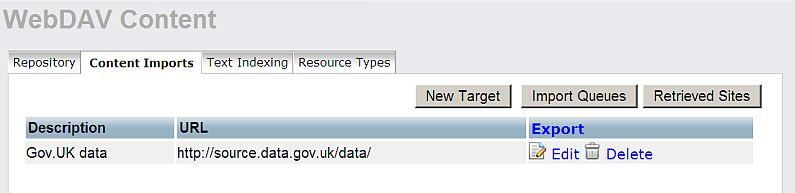
- Click "Import Queues".
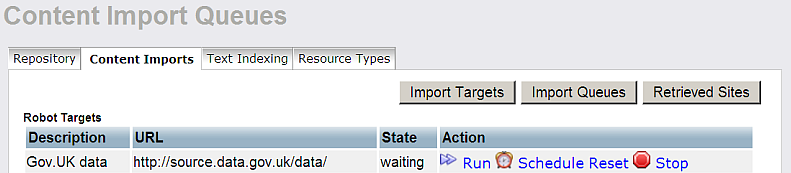
- For "Robot target" with label "Gov.UK data " click "Run".
- As result will be shown the status of the pages: retrieved, pending or respectively waiting.
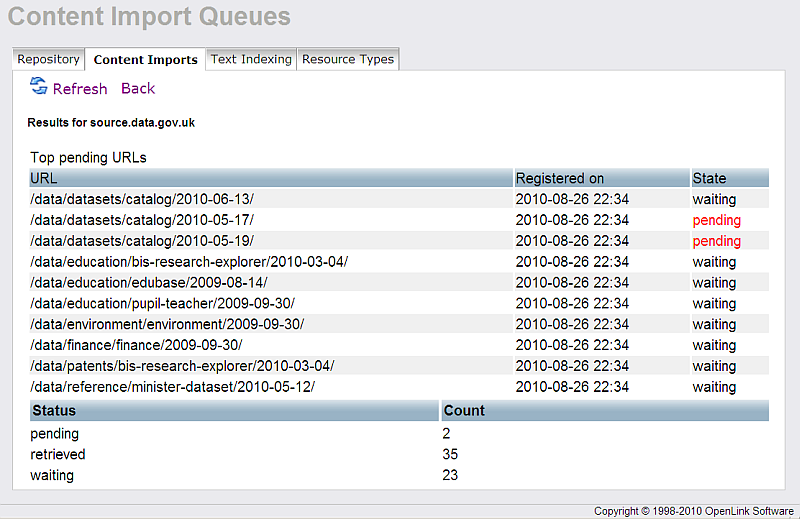
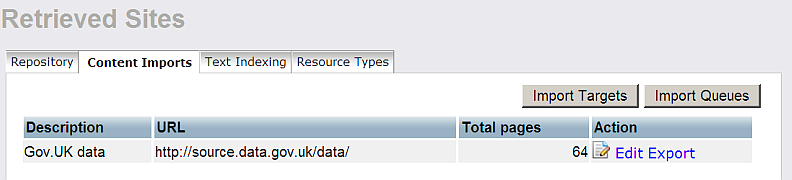
- Click "Retrieved Sites"
- As result should be shown the number of the total pages retrieved.
- Go to "Web Application Server" -> "Content Management" .
- Enter path:
DAV/home/demo/gov.uk
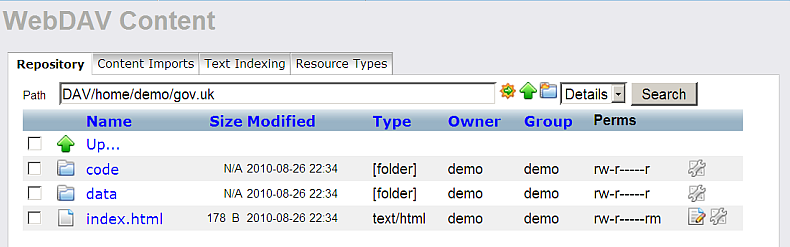
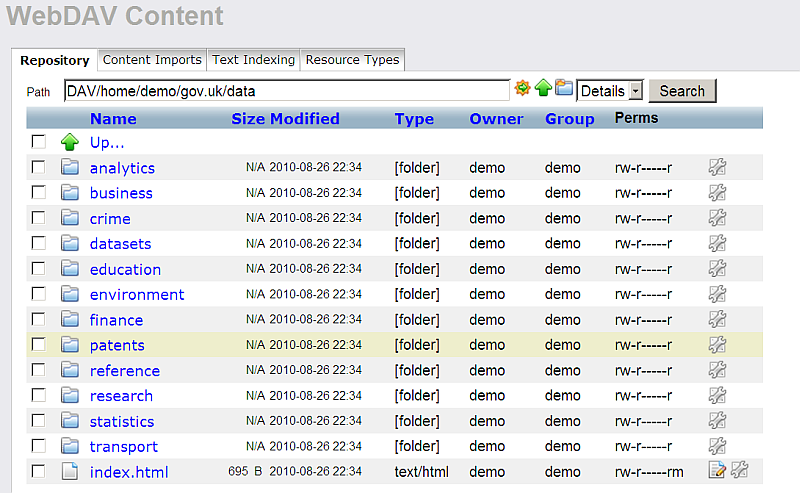
- Go to path:
DAV/home/demo/gov.uk/data
1 As result the retrieved content will be shown.
Related
- Setting up Crawler Jobs Guide using Conductor
- Setting up a Content Crawler Job to Add RDF Data to the Quad Store
- Setting up a Content Crawler Job to Retrieve Sitemaps (where the source includes RDFa)
- Setting up a Content Crawler Job to Retrieve Semantic Sitemaps (a variation of the standard sitemap)
- Setting up a Content Crawler Job to Retrieve Content from SPARQL endpoint