Virtuoso Programmer's Guide - RDF Middleware ("Sponger") (Part 2)
Contents (Part 2)
- Creating Custom Cartridges
- The Anatomy of a Cartridge
- Cartridge Hook Function
- Return Value
- Specifying the Target Graph
- Specifying & Retrieving Cartridge Specific Options
- API Keys
- XSLT - The Fulchrum
- Virtuoso's XML Infrastructure & Tools
- General Cartridge Pipeline
- Error Handling with Exit handlers
- Loading RDF into the Quad Store
- RDF_LOAD_RDFXML & TTLP
- Attribution
- Deleting Existing Graphs
- Proxy Service Data Expiration
- Cartridge Hook Function
- Ontology Mapping
- Passing Parameters to the XSLT Processor
- An RDF Description Template
- Defining A Generic Resource Description Wrapper
- Using SIOC as a Generic Container Model
- Naming Conventions for Sponger Generated Descriptions
- Registering & Configuring Cartridges
- Using SQL
- Using Conductor
- Installing Stylesheets
- Example - MusicBrainz: A Music Metadatabase
- MusicBrainz XML Web Service
- RDF Output
- Cartridge Hook Function
- XSLT Stylesheet
- Meta-Cartridges
- Registration
- Invocation
- Example - A Campaign Finance Meta-Cartridge for Freebase
- New York Times Campaign Finance (NYTCF) API
- Sponging Freebase
- Using OpenLink Data Explorer
- Using the Command Line
- Installing the Meta-Cartridge
- NYTCF Meta-Cartridge Functions
- NYTCF Meta-Cartridge Stylesheet
- Testing the Meta-Cartridge
- How The Meta-Cartridge Works
- The Anatomy of a Cartridge
Creating Custom Cartridges
The Sponger is fully extensible by virtue of its pluggable cartridge architecture. New data formats can be retrieved by creating new cartridges. While OpenLink is active in adding cartridges for new data sources, you are free to develop your own custom cartridges. Entity extractors can be built using Virtuoso PL, C/C++, Java or any other external language supported by Virtuoso's Server Extension API. Of course, Virtuoso's own entity extractors are written in Virtuoso PL.
The Anatomy of a Cartridge
Cartridge Hook Function
Every Virtuoso PL hook function used to plug a custom Sponger cartridge into the Virtuoso SPARQL engine must have a parameter list with the following parameters (the names of the parameters are not important, but their order and presence are) :
- in graph_iri varchar: the IRI of the graph being retrieved/crawled
- in new_origin_uri varchar: the URL of the document being retrieved
- in dest varchar: the destination/target graph IRI
- inout content any: the content of the retrieved document
- inout async_queue any: if the PingService? initialization parameter has been configured in the [SPARQL] section of the virtuoso.ini file, this is a pre-allocated asynchronous queue to be used to call the ping service
- inout ping_service any: the URL of a ping service, as assigned to the PingService? parameter in the [SPARQL] section of the virtuoso.ini configuration file. PingTheSemanticWeb? is an example of a such a service. See Appendix A for more details.
- inout api_key any: a string value specific to a given cartridge, contained in the RC_KEY column of the DB.DBA.SYS_RDF_CARTRIDGES table. The value can be a single string or a serialized array of strings providing cartridge specific data.
- inout opts any: cartridge specific options held in a Virtuoso/PL vector which acts as an array of key-value pairs.
Return Value
If the hook procedure returns zero the next cartridge will be tried. If the result is negative the sponging process stops, instructing the SPARQL engine that nothing was retrieved. If the result is positive the process stops, this time instructing the SPARQL engine that RDF data was successfully retrieved.
If your cartridge should need to test whether other cartridges are configured to handle a particular data source, the following extract taken from the RDF_LOAD_CALAIS hook procedure illustrates how you might do this:
if (xd is not null)
{
-- Sponging successful. Load Network Resource Data being fetched in Virtuoso quad store
DB.DBA.RM_RDF_LOAD_RDFXML (xd, new_origin_uri, coalesce (dest, graph_iri));
flag := 1;
}
declare ord any;
ord := (select RM_ID from DB.DBA.SYS_RDF_MAPPERS where
RM_HOOK = 'DB.DBA.RDF_LOAD_CALAIS');
for select RM_PATTERN from DB.DBA.SYS_RDF_MAPPERS where
RM_ID > ord and RM_TYPE = 'URL' and RM_ENABLED = 1 order by RM_ID do
{
if (regexp_match (RM_PATTERN, new_origin_uri) is not null)
-- try next candidate cartridge
flag := 0;
}
return flag;
Specifying the Target Graph
Two cartridge hook function parameters contain graph IRIs, graph_iri and dest. graph_iri identifies an input graph being crawled. dest holds the IRI specified in any input:grab-destination pragma defined to control the SPARQL processor's IRI dereferencing. The pragma overrides the default behaviour and forces all retrieved triples to be stored in a single graph, irrespective of their graph of origin.
So, under some circumstances depending on how the Sponger has been invoked and whether it is being used to crawl an existing RDF graph, or derive RDF data from a non-RDF data source, dest may be null.
Consequently, when loading Network Resource being fetched into the quad store, cartridges typically specify the graph to receive the data using the coalesce function which returns the first non-null parameter. e.g.
DB.DBA.RDF_LOAD_RDFXML (xd, new_origin_uri, coalesce (dest, graph_iri));Here xd is an RDF/XML string holding the fetched RDF.
Specifying & Retrieving Cartridge Specific Options
The hook function prototype allows cartridge specific data to be passed to a cartridge through the RM_OPTIONS parameter, a Virtuoso/PL vector which acts as a heterogeneous array.
In the following example, two options are passed, 'add-html-meta' and 'get-feeds' with both values set to 'no'.
insert soft DB.DBA.SYS_RDF_MAPPERS (
RM_PATTERN, RM_TYPE, RM_HOOK, RM_KEY, RM_DESCRIPTION, RM_OPTIONS
)
values (
'(text/html)|(text/xml)|(application/xml)|(application/rdf.xml)',
'MIME', 'DB.DBA.RDF_LOAD_HTML_RESPONSE', null, 'xHTML',
vector ('add-html-meta', 'no', 'get-feeds', 'no')
);
The RM_OPTIONS vector can be handled as an array of key-value pairs using the get_keyword function. get_keyword performs a case sensitive search for the given keyword at every even index of the given array. It returns the element following the keyword, i.e. the keyword value.
Using get_keyword, any options passed to the cartridge can be retrieved using an approach similar to that below:
create procedure DB.DBA.RDF_LOAD_HTML_RESPONSE (
in graph_iri varchar, in new_origin_uri varchar, in dest varchar,
inout ret_body any, inout aq any, inout ps any, inout _key any,
inout opts any )
{
declare get_feeds, add_html_meta;
...
get_feeds := add_html_meta := 0;
if (isarray (opts) and 0 = mod (length(opts), 2))
{
if (get_keyword ('get-feeds', opts) = 'yes')
get_feeds := 1;
if (get_keyword ('add-html-meta', opts) = 'yes')
add_html_meta := 1;
}
...
API Keys
Certain web services require applications to provide an API key to use the service. Flickr is one such service. Developers must register to obtain a key. See for instance http://developer.yahoo.com/flickr/. In order to cater for services which require an application key, the Cartridge Registry SYS_RDF_MAPPERS table includes an RM_KEY column to store any key required for a particular service. This value is passed to the service's cartridge through the _key parameter of the cartridge hook function.
Alternatively a cartridge can store a key value in the virtuoso.ini configuration file and retrieve it in the hook function.
The next example shows an extract from the Flickr cartridge hook function DB.DBA.RDF_LOAD_FLICKR_IMG and the use of an API key. Also, commented out, is a call to cfg_item_value() which illustrates how the API key could instead be stored and retrieved from the SPARQL section of the virtuoso.ini file.
create procedure DB.DBA.RDF_LOAD_FLICKR_IMG (
in graph_iri varchar, in new_origin_uri varchar, in dest varchar,
inout _ret_body any, inout aq any, inout ps any, inout _key any,
inout opts any )
{
declare xd, xt, url, tmp, api_key, img_id, hdr, exif any;
declare exit handler for sqlstate '*'
{
return 0;
};
tmp := sprintf_inverse (new_origin_uri,
'http://farm%s.static.flickr.com/%s/%s_%s.%s', 0);
img_id := tmp[2];
api_key := _key;
--cfg_item_value (virtuoso_ini_path (), 'SPARQL', 'FlickrAPIkey');
if (tmp is null or length (tmp) <> 5 or not isstring (api_key))
return 0;
url := sprintf('http://api.flickr.com/services/rest/?method=flickr.photos.getInfo&photo_id=%s&api_key=%s',img_id, api_key);
tmp := http_get (url, hdr);
XSLT - The Fulchrum
XSLT is the fulchrum of all OpenLink supplied cartridges. It provides the most convenient means of converting structured data extracted from web content by a cartridge's Entity Extractor into RDF.
Virtuoso's XML Infrastructure & Tools
Virtuoso's XML support and XSLT support are covered in detail in the on-line documentation. Virtuoso includes a highly capable XML parser and supports XPath, XQuery, XSLT and XML Schema validation.
Virtuoso supports extraction of XML documents from SQL datasets. A SQL long varchar, long xml or xmltype column in a database table can contain XML data as text or in a binary serialized format. A string representing a well-formed XML entity can be converted into an entity object representing the root node.
While Sponger cartridges will not normally concern themselves with handling XML extracted from SQL data, the ability to convert a string into an in-memory XML document is used extensively. The function xtree_doc(string) converts a string into such a document and returns a reference to the document's root. This document together with an appropriate stylesheet forms the input for the transformation of the extracted entities to RDF using XSLT. The input string to xtree_doc generally contains structured content derived from a web service.
Virtuoso XSLT Support
Virtuoso implements XSLT 1.0 transformations as SQL callable functions. The xslt() Virtuoso/PL function applies a given stylesheet to a given source XML document and returns the transformed document. Virtuoso provides a way to extend the abilities of the XSLT processor by creating user defined XPath functions. The functions xpf_extension() and xpf_extension_remove() allow addition and removal of XPath extension functions.
General Cartridge Pipeline
The broad pipeline outlined here reflects the steps common to most cartridges:
- Redirect from the requested URL to a Web service which returns XML
- Stream the content into an in-memory XML document
- Convert it to the required RDF/XML, expressed in the chosen ontology, using XSLT
- Encode the RDF/XML as UTF-8
- Load the RDF/XML into the quad store
The MusicBrainz cartridge typifies this approach. MusicBrainz is a community music metadatabase which captures information about artists, their recorded works, and the relationships between them. Artists always have a unique ID, so the URL http://musicbrainz.org/artist/4d5447d7-c61c-4120-ba1b-d7f471d385b9.html takes you directly to entries for John Lennon.
If you were to look at this page in your browser, you would see that the information about the artist contains no RDF data. However, the cartridge is configured to intercept requests to URLs of the form http://musicbrainz.org/([^/]*)/([^.]*) and redirect to the cartridge to fetch all the available information on the given artist, release, track or label.
The cartridge extracts entities by redirecting to the MusicBrainz XML Web Service using as the basis for the initial query the item ID, e.g. an artist or label ID, extracted from the original URL. Stripped to its essentials, the core of the cartridge is:
webservice_uri := sprintf ('http://musicbrainz.org/ws/1/%s/%s?type=xml&inc=%U',
kind, id, inc);
content := RDF_HTTP_URL_GET (webservice_uri, '', hdr, 'GET', 'Accept: */*');
xt := xtree_doc (content);
...
xd := DB.DBA.RDF_MAPPER_XSLT (registry_get ('_cartridges_path_') || 'xslt/mbz2rdf.xsl', xt);
...
xd := serialize_to_UTF8_xml (xd);
DB.DBA.RM_RDF_LOAD_RDFXML (xd, new_origin_uri, coalesce (dest, graph_iri));
In the above outline, RDF_HTTP_URL_GET sends a query to the MusicBrainz web service, using query parameters appropriate for the original request, and retrieves the response using HTTP GET.
The returned XML is parsed into an in-memory parse tree by xtree_doc. Virtuoso/PL function RDF_MAPPER_XSLT is a simple wrapper around the function xslt which sets the current user to dba before returning an XML document transformed by an XSLT stylesheet, in this case mbz2rdf.xsl. Function serialize_to_UTF8_xml changes the character set of the in-memory XML document to UTF8. Finally, RM_RDF_LOAD_RDFXML is a wrapper around RDF_LOAD_RDFXML which parses the content of an RDF/XML string into a sequence of RDF triples and loads them into the quad store. XSLT stylesheets are usually held in the DAV/VAD/cartridges/xslt/main folder of Virtuoso's WebDAV store. registry_get('cartridges_path') returns the Cartridges VAD path, 'DAV/VAD/cartridges', from the Virtuoso registry.
More detailed descriptions of these Virtuoso functions can be found in the section 'Useful Virtuoso Functions' later in this document, or in the on-line Virtuoso Functions Guide.
The MusicBrainz cartridge is explored in more depth in the Examples section presented later.
Error Handling with Exit Handlers
Virtuoso condition handlers determine the behaviour of a Virtuoso/PL procedure when a condition occurs. You can declare one or more condition handlers in a Virtuoso/PL procedure for general SQL conditions or specific SQLSTATE values. If a statement in your procedure raises an SQLEXCEPTION condition and you declared a handler for the specific SQLSTATE or SQLEXCEPTION condition the server passes control to that handler. If a statement in your Virtuoso/PL procedure raises an SQLEXCEPTION condition, and you have not declared a handler for the specific SQLSTATE or the SQLEXCEPTION condition, the server passes the exception to the calling procedure (if any). If the procedure call is at the top-level, then the exception is signaled to the calling client.
A number of different condition handler types can be declared (see the Virtuoso reference documentation for more details.) Of these, exit handlers are probably all you will need. An example is shown below which handles any SQLSTATE. Commented out is a debug statement which outputs the message describing the SQLSTATE.
create procedure DB.DBA.RDF_LOAD_SOCIALGRAPH (in graph_iri varchar, ...)
{
declare qr, path, hdr any;
...
declare exit handler for sqlstate '*'
{
-- dbg_printf ('%s', __SQL_MESSAGE);
return 0;
};
...
-- data extraction and mapping successful
return 1;
}
Exit handlers are used extensively in the Virtuoso supplied cartridges. They are useful for ensuring graceful failure when trying to convert content which may not conform to your expectations. The RDF_LOAD_FEED_SIOC procedure (which is used internally by several cartridges) shown below uses this approach:
-- /* convert the feed in rss 1.0 format to sioc */
create procedure DB.DBA.RDF_LOAD_FEED_SIOC (in content any, in iri varchar, in graph_iri varchar, in is_disc int := '')
{
declare xt, xd any;
declare exit handler for sqlstate '*'
{
goto no_sioc;
};
xt := xtree_doc (content);
xd := DB.DBA.RDF_MAPPER_XSLT (
registry_get ('_cartridges_path_') || 'xslt/feed2sioc.xsl', xt,
vector ('base', graph_iri, 'isDiscussion', is_disc));
xd := serialize_to_UTF8_xml (xd);
DB.DBA.RM_RDF_LOAD_RDFXML (xd, iri, graph_iri);
return 1;
no_sioc:
return 0;
}
Loading RDF into the Quad Store
RDF_LOAD_RDFXML & TTLP
The two main Virtuoso/PL functions used by the cartridges for loading RDF data into the Virtuoso quad store are DB.DBA.TTLP and DB.DBA.RDF_LOAD_RDFXML. Multithreaded versions of these functions, DB.DBA.TTLP_MT and DB.DBA.RDF_LOAD_RDFXML_MT, are also available.
RDF_LOAD_RDFXML parses the content of an RDF/XML string as a sequence of RDF triples and loads then into the quad store. TTLP parses TTL (Turtle or N3) and places its triples into quad storage. Ordinarily, cartridges use RDF_LOAD_RDFXML. However there may be occasions where you want to insert statements written as TTL, rather than RDF/XML, in which case you should use TTLP.Attribution
Many of the OpenLink supplied cartridges actually use RM_RDF_LOAD_RDFXML to load data into the quad store. This is a thin wrapper around RDF_LOAD_RDFXML which includes in the generated graph an indication of the external ontologies being used. The attribution takes the form:
<ontologyURI> a opl:DataSource . <spongedResourceURI> rdfs:isDefinedBy <ontologyURI> . <ontologyURI> opl:hasNamespacePrefix "<ontologyPrefix>" .
where prefix opl: denotes the ontology http://www.openlinksw.com/schema/attribution#.
Deleting Existing Graphs
Before loading Network Resource being fetched into a graph, you may want to delete any existing graph with the same URI.
To do so, select the 'RDF' > 'Graphs' menu commands in Conductor, then use the 'Delete' command for the appropriate graph.
Alternatively, you can use one of the following SQL commands:
sparql clear graph
or
delete from DB.DBA.RDF_QUAD where G = DB.DBA.RDF_MAKE_IID_OF_QNAME (graph_iri);
Proxy Service Data Expiration
When the Proxy Service is invoked by a user agent, the Sponger records the expiry date of the imported data in the table DB.DBA.SYS_HTTP_SPONGE. The data invalidation rules conform to those of traditional HTTP clients (Web browsers). The data expiration time is determined based on subsequent data fetches of the same resource. The first data retrieval records the 'expires' header. On subsequent fetches, the current time is compared to the expiration time stored in the local cache. If HTTP 'expires' header data isn't returned by the source data server, the Sponger will derive its own expiration time by evaluating the 'date' header and 'last-modified' HTTP headers.
Ontology Mapping
After extracting entities from a web resource and converting them to an in-memory XML document, the entities must be transformed to the target ontology using XSLT and an appropriate stylesheet. A typical call sequence would be:
xt := xtree_doc (content);
...
xd := DB.DBA.RDF_MAPPER_XSLT (registry_get ('_cartridges_path_') || 'xslt/mbz2rdf.xsl', xt);
Because of the wide variation in the data mapped by cartridges, it is not possible to present a typical XSL stylesheet outline. The Examples section presented later includes detailed extracts from the MusicBrainz cartridge's stylesheet which provide a good example of how to map to an ontology. Rather than attempting to be an XSLT tutorial, the material which follows offers some general guidelines.
Passing Parameters to the XSLT Processor
Virtuoso's XSLT processor will accept default values for global parameters from the optional third argument of the xslt() function. This argument, if specified, must be a vector of parameter names and values of the form vector(name1, value1,... nameN, valueN), where name1 ... nameN must be of type varchar, and value1 ... valueN may be of any Virtuoso datatype, but may not be null.
This extract from the Crunchbase cartridge shows how parameters may be passed to the XSLT processor. The function RDF_MAPPER_XSLT (in xslt varchar, inout xt any, in params any := null) passes the parameters vector directly to xslt().
xt := DB.DBA.RDF_MAPPER_XSLT (
registry_get ('_cartridges_path_') || 'xslt/main/crunchbase2rdf.xsl', xt,
vector ('baseUri', coalesce (dest, graph_iri), 'base', base, 'suffix', suffix)
);
The corresponding stylesheet crunchbase2rdf.xsl retrieves the parameters baseUri, base and suffix as follows:
... <xsl:output method="xml" indent="yes" /> <xsl:variable name="ns">http://www.crunchbase.com/</xsl:variable> <xsl:param name="baseUri" /> <xsl:param name="base"/> <xsl:param name="suffix"/> <xsl:template name="space-name"> ...
An RDF Description Template
Defining A Generic Resource Description Wrapper
Many of the OpenLink cartridges create a resource description formed to a common "wrapper" template which describes the relationship between the (usually) non-RDF source resource being fetched and the RDF description generated by the Sponger. The wrapper is appropriate for resources which can broadly be conceived as documents. It provides a generic minimal description of the source document, but also links to the much more detailed description provided by the Sponger. So, instead of just emitting a resource description, the Sponger factors the container into the generated graph constituting the RDF description.
The template is depicted below:

To generate an RDF description corresponding to the wrapper template, a stylesheet containing the following block of instructions is used. This extract is taken from the eBay cartridge's stylesheet, ebay2rdf.xsl. Many of the OpenLink cartridges follow a similar pattern.
<xsl:param name="baseUri"/>
...
<xsl:variable name="resourceURL">
<xsl:value-of select="$baseUri"/>
</xsl:variable>
...
<xsl:template match="/">
<rdf:RDF>
<rdf:Description rdf:about="{$resourceURL}">
<rdf:type rdf:resource="Document"/>
<rdf:type rdf:resource="Document"/>
<rdf:type rdf:resource="Container"/>
<sioc:container_of rdf:resource="{vi:proxyIRI ($resourceURL)}"/>
<foaf:primaryTopic rdf:resource="{vi:proxyIRI ($resourceURL)}"/>
<dcterms:subject rdf:resource="{vi:proxyIRI ($resourceURL)}"/>
</rdf:Description>
<rdf:Description rdf:about="{vi:proxyIRI ($resourceURL)}">
<rdf:type rdf:resource="Item"/>
<sioc:has_container rdf:resource="{$resourceURL}"/>
<xsl:apply-templates/>
</rdf:Description>
</rdf:RDF>
</xsl:template>
...
Using SIOC as a Generic Container Model
The generic resource description wrapper just described uses SIOC to establish the container/contained relationship between the source resource and the generated graph. Although the most important classes for the generic wrapper are obviously Container and Item, SIOC provides a generic data model of containers, items, item types, and associations between items which can be combined with other vocabularies such as FOAF and Dublin Core.
SIOC defines a number of other classes, such as User, UserGroup?, Role, Site, Forum and Post. A separate SIOC types module (T-SIOC) extends the SIOC Core ontology by defining subclasses and subproperties of SIOC terms. Subclasses include: AddressBook?, BookmarkFolder?, Briefcase, EventCalendar?, ImageGallery?, Wiki, Weblog, BlogPost?, Wiki plus many others.
OpenLink Data Spaces (ODS) uses SIOC extensively as a data space "glue" ontology to describe the base data and containment hierarchy of all the items managed by ODS applications (Data Spaces). For example, ODS-Weblog is an application of type sioc:Forum. Each ODS-Weblog application instance contains blogs of type sioct:Weblog. Each blog is a sioc:container_of posts of type sioc:Post.
Generally, when deciding how to describe resources handled by your own custom cartridge, SIOC provides a useful framework for the description which complements the SIOC-based container model adopted throughout the ODS framework.
For full details of ODS, the Virtuoso Wiki topic Ods provides a useful starting point. For details of the SIOC mappings used by ODS, please refer to the ODS SIOC Reference.
Naming Conventions for Sponger Generated Descriptions
As can be seen from the stylesheet extract just shown, the URI of the resource description generated by the Sponger to describe the Network Resource being fetched is given by the function {vi:proxyIRI ($resourceURL)} where resourceURL is the URL of the original Network resource being fetched.
proxyIRI is an XPath extension function defined in rdf_mappers.sql as
xpf_extension ('http://www.openlinksw.com/virtuoso/xslt/:proxyIRI', 'DB.DBA.RDF_SPONGE_PROXY_IRI');
which maps to the Virtuoso/PL procedure DB.DBA.RDF_SPONGE_PROXY_IRI.
This procedure in turn generates a resource description URI which typically takes the form:
http://<hostName:port>/about/rdf/<resourceURL>#this
Registering & Configuring Cartridges
Once you have developed a cartridge, you must register it in the Cartridge Registry to have the SPARQL processor recognise and use it.
You should have compiled your cartridge hook function first by issuing a "create procedure DB.DBA.RDF_LOAD_xxx ..." command through one of Virtuoso's SQL interfaces.
You can create the required Cartridge Registry entry either by adding a row to the SYS_REF_MAPPERS table directly using SQL, or by using the Conductor UI.
Using SQL
If you choose register your cartridge using SQL, possibly as part of a Virtuoso/PL script, the required SQL will typically mirror one of the following INSERT commands.
Below, a cartridge for OpenCalais? is being installed which will be tried when the MIME type of the data being fetched is one of text/plain, text/xml or text/html. (The definition of the SYS_RDF_MAPPERS table was introduced earlier in section 'Cartridge Registry'.)
insert soft DB.DBA.SYS_RDF_MAPPERS ( RM_PATTERN, RM_TYPE, RM_HOOK, RM_KEY, RM_DESCRIPTION, RM_ENABLED) values ( '(text/plain)|(text/xml)|(text/html)', 'MIME', 'DB.DBA.RDF_LOAD_CALAIS', null, 'Opencalais', 1);
As an alternative to matching on the content's MIME type, candidate cartridges to be tried in the conversion pipeline can be identified by matching the data source URL against a URL pattern stored in the cartridge's entry in the Cartridge Registry.
insert soft DB.DBA.SYS_RDF_MAPPERS ( RM_PATTERN, RM_TYPE, RM_HOOK, RM_KEY, RM_DESCRIPTION, RM_OPTIONS) values ( '(http://api.crunchbase.com/v/1/.*)|(http://www.crunchbase.com/.*)', 'URL', 'DB.DBA.RDF_LOAD_CRUNCHBASE', null, 'CrunchBase', null);
The value of RM_ID to set depends on where in the cartridge invocation order you want to position a particular cartridge. RM_ID should be set lower than 10028 to ensure the cartridge is tried before the ODS-Briefcase (WebDAV) metadata extractor, which is always the last mapper to be tried if no preceding cartridge has been successful.
update DB.DBA.SYS_RDF_MAPPERS set RM_ID = 1000 where RM_HOOK = 'DB.DBA.RDF_LOAD_BIN_DOCUMENT';
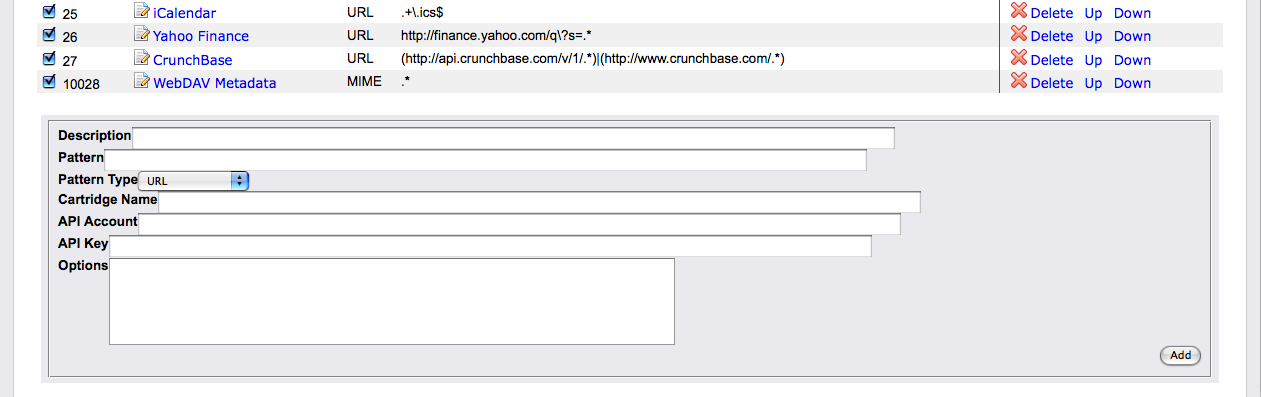
Using Conductor
Cartridges can be added manually using the 'Add' panel of the 'Cartridges' screen.

Installing Stylesheets
Although you could place your cartridge stylesheet in any folder configured to be accessible by Virtuoso, the simplest option is to upload them to the DAV/VAD/cartridges/xslt/main folder using the WebDAV browser accessible from the Conductor UI.
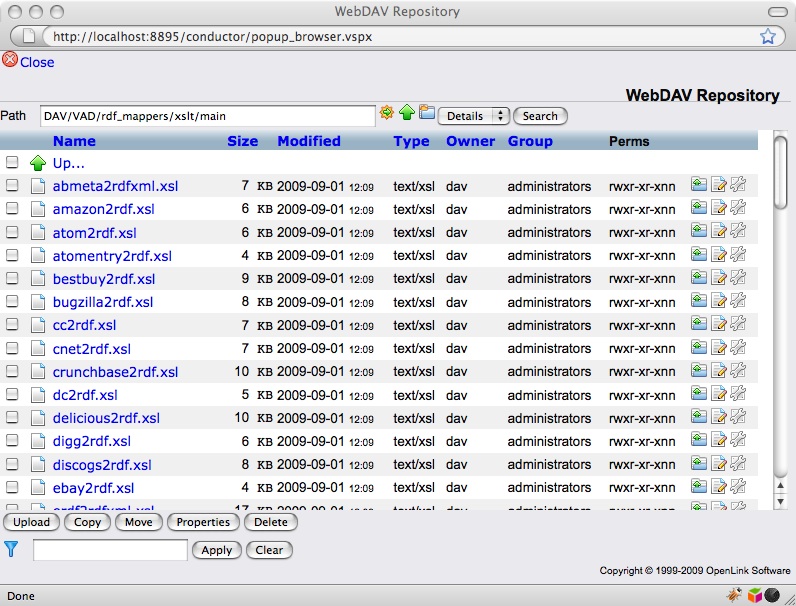
Should you wish to locate your stylesheets elsewhere, ensure that the DirsAllowed? setting in the virtuoso.ini file is configured appropriately.
Example - MusicBrainz: A Music Metadatabase
To illustrate some of the material presented so far, we'll delve deeper into the MusicBrainz cartridge mentioned earlier.
MusicBrainz XML Web Service
The cartridge extracts data through the MusicBrainz XML Web Service using, as the basis for the initial query, an item type and MBID (MusicBrainz ID) extracted from the original URI submitted to the RDF proxy. A range of item types are supported including artist, release and track.
Using the album "Imagine" by John Lennon as an example, a standard HTML description of the album (which has an MBID of f237e6a0-4b0e-4722-8172-66f4930198bc) can be retrieved direct from MusicBrainz using the URL:
http://musicbrainz.org/release/f237e6a0-4b0e-4722-8172-66f4930198bc.html
Alternatively, information can be extracted in XML form through the web service. A description of the tracks on the album can be obtained with the query:
http://musicbrainz.org/ws/1/release/f237e6a0-4b0e-4722-8172-66f4930198bc?type=xml&inc=tracks
The XML returned by the web service is shown below (only the first two tracks are shown for brevity):
<?xml version="1.0" encoding="UTF-8"?>
<metadata xmlns="http://musicbrainz.org/ns/mmd-1.0#"
xmlns:ext="http://musicbrainz.org/ns/ext-1.0#">
<release id="f237e6a0-4b0e-4722-8172-66f4930198bc" type="Album Official" >
<title>Imagine</title>
<text-representation language="ENG" script="Latn"/>
<asin>B0000457L2</asin>
<track-list>
<track id="b88bdafd-e675-4c6a-9681-5ea85ab99446">
<title>Imagine</title>
<duration>182933</duration>
</track>
<track id="b38ce90d-3c47-4ccd-bea2-4718c4d34b0d">
<title>Crippled Inside</title>
<duration>227906</duration>
</track>
. . .
</track-list>
</release>
</metadata>
Although, as shown above, MusicBrainz defines its own XML Metadata Format to represent music metadata, the MusicBrainz sponger converts the raw data to a subset of the Music Ontology, an RDF vocabulary which aims to provide a set of core classes and properties for describing music on the Semantic Web. Part of the subset used is depicted in the following RDF graph (representing in this case a John Cale album).
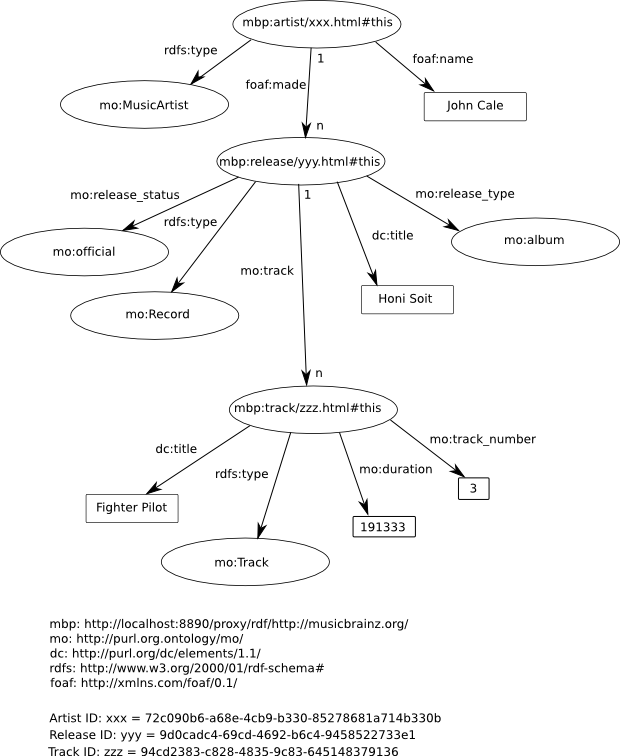
With the prefix mo: denoting the Music Ontology at http://purl.org/ontology/mo/, it can be seen that artists are represented by instances of class mo:Artist, their albums, records etc. by instances of class mo:Release and tracks on these releases by class mo:Track. The property foaf:made links an artist and his/her releases. Property mo:track links a release with the tracks it contains.
RDF Output
An RDF description of the album can be obtained by sponging the same URL, i.e. by submitting it to the Sponger's proxy interface using the URL:
The extract below shows part of the (reorganized) RDF output returned by the Sponger for "Imagine". Only the album's title track is included.
<?xml version="1.0" encoding="utf-8" ?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"> <rdf:Description rdf:about="http://musicbrainz.org/release/f237e6a0-4b0e-4722-8172-66f4930198bc.html"> <rdf:type rdf:resource="http://xmlns.com/foaf/0.1/Document"/> </rdf:Description> <rdf:Description rdf:about="http://musicbrainz.org/release/f237e6a0-4b0e-4722-8172-66f4930198bc.html"> <foaf:primaryTopic xmlns:foaf="http://xmlns.com/foaf/0.1/" rdf:resource="http://demo.openlinksw.com/about/rdf/http://musicbrainz.org/release/f237e6a0-4b0e-4722-8172-66f4930198bc.html#this"/> </rdf:Description> <rdf:Description rdf:about="http://purl.org/ontology/mo/"> <rdf:type rdf:resource="http://www.openlinksw.com/schema/attribution#DataSource"/> </rdf:Description> ... <rdf:Description rdf:about="http://musicbrainz.org/release/f237e6a0-4b0e-4722-8172-66f4930198bc.html"> <rdfs:isDefinedBy rdf:resource="http://purl.org/ontology/mo/"/> </rdf:Description> ... <!-- Record description --> <rdf:Description rdf:about="http://demo.openlinksw.com/about/rdf/http://musicbrainz.org/release/f237e6a0-4b0e-4722-8172-66f4930198bc.html#this"> <rdf:type rdf:resource="http://purl.org/ontology/mo/Record"/> </rdf:Description> <rdf:Description rdf:about="http://demo.openlinksw.com/about/rdf/http://musicbrainz.org/release/f237e6a0-4b0e-4722-8172-66f4930198bc.html#this"> <dc:title xmlns:dc="http://purl.org/dc/elements/1.1/">Imagine</dc:title> </rdf:Description> <rdf:Description rdf:about="http://demo.openlinksw.com/about/rdf/http://musicbrainz.org/release/f237e6a0-4b0e-4722-8172-66f4930198bc.html#this"> <mo:release_status xmlns:mo="http://purl.org/ontology/mo/" rdf:resource="http://purl.org/ontology/mo/official"/> </rdf:Description> <rdf:Description rdf:about="http://demo.openlinksw.com/about/rdf/http://musicbrainz.org/release/f237e6a0-4b0e-4722-8172-66f4930198bc.html#this"> <mo:release_type xmlns:mo="http://purl.org/ontology/mo/" rdf:resource="http://purl.org/ontology/mo/album"/> </rdf:Description> <!-- Title track description --> <rdf:Description rdf:about="http://demo.openlinksw.com/about/rdf/http://musicbrainz.org/release/f237e6a0-4b0e-4722-8172-66f4930198bc.html#this"> <mo:track xmlns:mo="http://purl.org/ontology/mo/" rdf:resource="http://demo.openlinksw.com/about/rdf/http://musicbrainz.org/track/b88bdafd-e675-4c6a-9681-5ea85ab99446.html#this"/> </rdf:Description> <rdf:Description rdf:about="http://demo.openlinksw.com/about/rdf/http://musicbrainz.org/track/b88bdafd-e675-4c6a-9681-5ea85ab99446.html#this"> <rdf:type rdf:resource="http://purl.org/ontology/mo/Track"/> </rdf:Description> <rdf:Description rdf:about="http://demo.openlinksw.com/about/rdf/http://musicbrainz.org/track/b88bdafd-e675-4c6a-9681-5ea85ab99446.html#this"> <dc:title xmlns:dc="http://purl.org/dc/elements/1.1/">Imagine</dc:title> </rdf:Description> <rdf:Description rdf:about="http://demo.openlinksw.com/about/rdf/http://musicbrainz.org/track/b88bdafd-e675-4c6a-9681-5ea85ab99446.html#this"> <mo:track_number xmlns:mo="http://purl.org/ontology/mo/">1</mo:track_number> </rdf:Description> <rdf:Description rdf:about="http://demo.openlinksw.com/about/rdf/http://musicbrainz.org/track/b88bdafd-e675-4c6a-9681-5ea85ab99446.html#this"> <mo:duration xmlns:mo="http://purl.org/ontology/mo/" rdf:datatype="http://www.w3.org/2001/XMLSchema#integer">182933</mo:duration> </rdf:Description> </rdf:RDF>
Cartridge Hook Function
The cartridge's hook function is listed below. It is important to note that MusicBrainz supports a variety of query types, each of which returns a different set of information, depending on the item type being queried. Full details can be found on the MusicBrainz? site. The sponger cartridge is capable of handling all the query types supported by MusicBrainz? and is intended to be used in a drill-down scenario, as would be the case when using an RDF browser such as the OpenLink Data Explorer (ODE). This example focuses primarily on the types release and track.
create procedure DB.DBA.RDF_LOAD_MBZ (
in graph_iri varchar, in new_origin_uri varchar, in dest varchar,
inout _ret_body any, inout aq any, inout ps any, inout _key any,
inout opts any)
{
declare kind, id varchar;
declare tmp, incs any;
declare uri, cnt, hdr, inc, xd, xt varchar;
tmp := regexp_parse ('http://musicbrainz.org/([^/]*)/([^\.]+)', new_origin_uri, 0);
declare exit handler for sqlstate '*'
{
-- dbg_printf ('%s', __SQL_MESSAGE);
return 0;
};
if (length (tmp) < 6)
return 0;
kind := subseq (new_origin_uri, tmp[2], tmp[3]);
id := subseq (new_origin_uri, tmp[4], tmp[5]);
incs := vector ();
if (kind = 'artist')
{
inc := 'aliases artist-rels label-rels release-rels track-rels url-rels';
incs :=
vector (
'sa-Album', 'sa-Single', 'sa-EP', 'sa-Compilation', 'sa-Soundtrack',
'sa-Spokenword', 'sa-Interview', 'sa-Audiobook', 'sa-Live', 'sa-Remix', 'sa-Other'
, 'va-Album', 'va-Single', 'va-EP', 'va-Compilation', 'va-Soundtrack',
'va-Spokenword', 'va-Interview', 'va-Audiobook', 'va-Live', 'va-Remix', 'va-Other'
);
}
else if (kind = 'release')
inc := 'artist counts release-events discs tracks artist-rels label-rels release-rels track-rels url-rels track-level-rels labels';
else if (kind = 'track')
inc := 'artist releases puids artist-rels label-rels release-rels track-rels url-rels';
else if (kind = 'label')
inc := 'aliases artist-rels label-rels release-rels track-rels url-rels';
else
return 0;
if (dest is null)
delete from DB.DBA.RDF_QUAD where G = DB.DBA.RDF_MAKE_IID_OF_QNAME (graph_iri);
DB.DBA.RDF_LOAD_MBZ_1 (graph_iri, new_origin_uri, dest, kind, id, inc);
DB.DBA.TTLP (sprintf ('<%S> <http://xmlns.com/foaf/0.1/primaryTopic> <%S> .\n<%S> a <http://xmlns.com/foaf/0.1/Document> .',
new_origin_uri, DB.DBA.RDF_SPONGE_PROXY_IRI (new_origin_uri), new_origin_uri),
'', graph_iri);
foreach (any inc1 in incs) do
{
DB.DBA.RDF_LOAD_MBZ_1 (graph_iri, new_origin_uri, dest, kind, id, inc1);
}
return 1;
};
The hook function uses a subordinate procedure RDF_LOAD_MBZ_1:
create procedure DB.DBA.RDF_LOAD_MBZ_1 (in graph_iri varchar, in new_origin_uri varchar,
in dest varchar, in kind varchar, in id varchar, in inc varchar)
{
declare uri, cnt, xt, xd, hdr any;
uri := sprintf ('http://musicbrainz.org/ws/1/%s/%s?type=xml&inc=%U', kind, id, inc);
cnt := RDF_HTTP_URL_GET (uri, '', hdr, 'GET', 'Accept: */*');
xt := xtree_doc (cnt);
xd := DB.DBA.RDF_MAPPER_XSLT (registry_get ('_cartridges_path_') || 'xslt/main/mbz2rdf.xsl', xt,
vector ('baseUri', new_origin_uri));
xd := serialize_to_UTF8_xml (xd);
DB.DBA.RM_RDF_LOAD_RDFXML (xd, new_origin_uri, coalesce (dest, graph_iri));
};
XSLT Stylesheet
The key sections of the MusicBrainz? XSLT template relevant to this example are listed below. Only the sections relating to an artist, his releases, or the tracks on those releases, are shown.
<!DOCTYPE xsl:stylesheet [
<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">
<!ENTITY rdf "http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<!ENTITY rdfs "http://www.w3.org/2000/01/rdf-schema#">
<!ENTITY mo "http://purl.org/ontology/mo/">
<!ENTITY foaf "http://xmlns.com/foaf/0.1/">
<!ENTITY mmd "http://musicbrainz.org/ns/mmd-1.0#">
<!ENTITY dc "http://purl.org/dc/elements/1.1/">
]>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:vi="http://www.openlinksw.com/virtuoso/xslt/"
xmlns:rdf=""
xmlns:rdfs=""
xmlns:foaf=""
xmlns:mo=""
xmlns:mmd=""
xmlns:dc=""
>
<xsl:output method="xml" indent="yes" />
<xsl:variable name="base" select="'http://musicbrainz.org/'"/>
<xsl:variable name="uc">ABCDEFGHIJKLMNOPQRSTUVWXYZ</xsl:variable>
<xsl:variable name="lc">abcdefghijklmnopqrstuvwxyz</xsl:variable>
<xsl:template match="/mmd:metadata">
<rdf:RDF>
<xsl:apply-templates />
</rdf:RDF>
</xsl:template>
...
<xsl:template match="mmd:artist[@type='Person']">
<mo:MusicArtist rdf:about="{vi:proxyIRI (concat($base,'artist/',@id,'.html'))}">
<foaf:name><xsl:value-of select="mmd:name"/></foaf:name>
<xsl:for-each select="mmd:release-list/mmd:release|mmd:relation-list[@target-type='Release']/mmd:relation/mmd:release">
<foaf:made rdf:resource="{vi:proxyIRI (concat($base,'release/',@id,'.html'))}"/>
</xsl:for-each>
</mo:MusicArtist>
<xsl:apply-templates />
</xsl:template>
<xsl:template match="mmd:release">
<mo:Record rdf:about="{vi:proxyIRI (concat($base,'release/',@id,'.html'))}">
<dc:title><xsl:value-of select="mmd:title"/></dc:title>
<mo:release_type rdf:resource="{translate (substring-before (@type, ' '),
$uc, $lc)}"/>
<mo:release_status rdf:resource="{translate (substring-after (@type, ' '), $uc,
$lc)}"/>
<xsl:for-each select="mmd:track-list/mmd:track">
<mo:track rdf:resource="{vi:proxyIRI (concat($base,'track/',@id,'.html'))}"/>
</xsl:for-each>
</mo:Record>
<xsl:apply-templates select="mmd:track-list/mmd:track"/>
</xsl:template>
<xsl:template match="mmd:track">
<mo:Track rdf:about="{vi:proxyIRI (concat($base,'track/',@id,'.html'))}">
<dc:title><xsl:value-of select="mmd:title"/></dc:title>
<mo:track_number><xsl:value-of select="position()"/></mo:track_number>
<mo:duration rdf:datatype="integer">
<xsl:value-of select="mmd:duration"/>
</mo:duration>
<xsl:if test="artist[@id]">
<foaf:maker rdf:resource="{vi:proxyIRI (concat ($base, 'artist/',
artist/@id, '.html'))}"/>
</xsl:if>
<mo:musicbrainz rdf:resource="{vi:proxyIRI (concat ($base, 'track/', @id, '.html'))}"/>
</mo:Track>
</xsl:template>
...
<xsl:template match="text()"/>
</xsl:stylesheet>
Meta-Cartridges
So far the discussion has centred on 'primary' cartridges. However, Virtuoso supports an alternative type of cartridge, a 'meta-cartridge'. The way a meta-cartridge operates is essentially the same as a primary cartridge, that is it has a cartridge hook function with the same signature and its inserts data into the quad store through entity extraction and ontology mapping as before. Where meta-cartridges differ from primary cartridges is in their intent and their position in the cartridge invocation pipeline.
The purpose of meta-cartridges is to enrich graphs produced by other (primary) cartridges. They serve as general post-processors to add additional information about selected entities in an RDF graph. For instance, a particular meta-cartridge might be designed to search for entities of type 'umbel:Country' in a given graph, and then add additional statements about each country it finds, where the information contained in these statements is retrieved from the web service targetted by the meta-cartridge. One such example might be a 'World Bank' meta-cartridge which adds information relating to a country's GDP, its exports of goods and services as a percentage of GDP etc; retrieved using the World Bank web service API. In order to benefit from the World Bank meta-cartridge, any primary cartridge which might generate instance data relating to countries should ensure that each country instance it handles is also described as being of rdf:type 'umbel:Country'. Here, the UMBEL (Upper Mapping and Binding Exchange Layer) ontology is used as a data-source-agnostic classification system. It provides a core set of 20,000+ subject concepts which act as "a fixed set of reference points in a global knowledge space". The use of UMBEL in this way serves to decouple meta-cartridges from primary cartridges and data source specific ontologies.
Virtuoso includes numerous meta-cartridges for augmenting source graphs using data retrieved from lookup services, examples being UMBEL and OpenCalais.
Note: Meta-cartridges are only available in the closed source version of Virtuoso. The meta-cartridge feature is disabled in Virtuoso Open Source edition (VOS). Meta-cartridge stylesheets reside in DAV/VAD/cartridges/xslt/meta. In VOS, this directory is empty.Registration
Meta-cartridges can be registered through the Conductor UI.

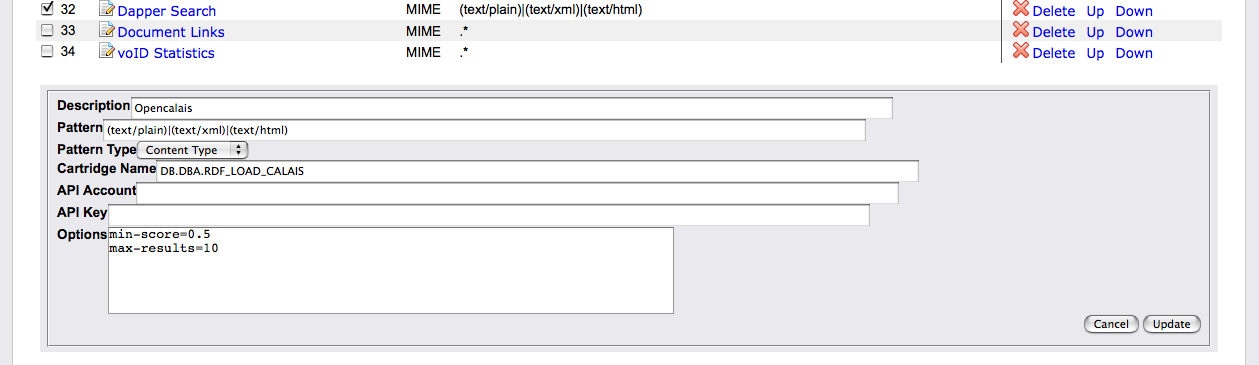
Alternatively, a meta-cartridge can be registered programmatically by adding an entry to the RDF_META_CARTRIDGES table, which fulfills a role similar to the SYS_RDF_MAPPERS table used by primary cartridges. The structure of the table, and the meaning and use of its columns, are similar to SYS_RDF_MAPPERS. The meta-cartridge hook function signature is identical to that for primary cartridges.
The RDF_META_CARTRIDGES table definition is as follows:
create table DB.DBA.RDF_META_CARTRIDGES (
MC_ID INTEGER IDENTITY, -- meta-cartridge ID. Determines the order of the
meta-cartridge's invocation in the Sponger
processing chain
MC_SEQ INTEGER IDENTITY,
MC_HOOK VARCHAR, -- fully qualified Virtuoso/PL function name
MC_TYPE VARCHAR,
MC_PATTERN VARCHAR, -- a REGEX pattern to match resource URL or
MIME type
MC_KEY VARCHAR, -- API specific key to use
MC_OPTIONS ANY, -- meta-cartridge specific options
MC_DESC LONG VARCHAR, -- meta-cartridge description (free text)
MC_ENABLED INTEGER -- a 0 or 1 integer flag to exclude or include
meta-cartridge from Sponger processing chain
);
Invocation
Meta-cartridges are invoked through the post-processing hook procedure RDF_LOAD_POST_PROCESS which is called, for every document retrieved, after RDF_LOAD_RDFXML loads fetched data into the quad store.
Cartridges in the meta-cartridge registry (RDF_META_CARTRIDGES) are configured to match a given MIME type or URI pattern. Matching meta-cartridges are invoked in order of their MC_SEQ value. Ordinarily a meta-cartridge should return 0, in which case the next meta-cartridge in the post-processing chain will be invoked. If it returns 1 or -1, the post-processing stops and no further meta-cartridges are invoked.
The order of processing by the Sponger cartridge pipeline is thus:
- Try to get RDF in the form of TTL or RDF/XML. If RDF is retrieved if go to step 3
- Try generating RDF through the Sponger primary cartridges as before (see Figure 3).
- Post-process the RDF using meta-cartridges in order of their MC_SEQ value. If a meta-cartridge returns 1 or -1, stop the post-processing chain.
Notice that meta-cartridges may be invoked even if primary cartridges are not.
Example - A Campaign Finance Meta-Cartridge for Freebase
Note
The example which follows builds on a Freebase Sponger cartridge developed prior to the announcement of Freebase's support for generating Linked Data through the endpoint http://rdf.freebase.com/ . The OpenLink cartridge has since evolved to reflect these changes. A snapshot of the Freebase cartridge and stylesheet compatible with this example can be found in Appendix C.Freebase is an open community database of the world's information which serves facts and statistics rather than articles. Its designers see this difference in emphasis from article-oriented databases as beneficial for developers wanting to use Freebase facts in other websites and applications.
Virtuoso includes a Freebase cartridge in the cartridges VAD. The aim of the example cartridge presented here is to provide a lightweight meta-cartridge that is used to conditionally add triples to graphs generated by the Freebase cartridge, if Freebase is describing a U.S. senator.
New York Times Campaign Finance (NYTCF) API
The New York Times Campaign Finance (NYTCF) API allows you to retrieve contribution and expenditure data based on United States Federal Election Commission filings. You can retrieve totals for a particular presidential candidate, see aggregates by ZIP code or state, or get details on a particular donor.
The API supports a number of query types. To keep this example from being overly long, the meta-cartridge supports just one of these - a query for the candidate details. An example query and the resulting output follow:
Query:
http://api.nytimes.com/svc/elections/us/v2/president/2008/finances/candidates/obama,barack.xml?api-key=xxxx Result:
<result_set>
<status>OK</status>
<copyright>
Copyright (c) 2008 The New York Times Company. All Rights Reserved.
</copyright>
<results>
<candidate>
<candidate_name>Obama, Barack</candidate_name>
<committee_id>C00431445</committee_id>
<party>D</party>
<total_receipts>468841844</total_receipts>
<total_disbursements>391437723.5</total_disbursements>
<cash_on_hand>77404120</cash_on_hand>
<net_individual_contributions>426902994</net_individual_contributions>
<net_party_contributions>150</net_party_contributions>
<net_pac_contributions>450</net_pac_contributions>
<net_candidate_contributions>0</net_candidate_contributions>
<federal_funds>0</federal_funds>
<total_contributions_less_than_200>222694981.5</total_contributions_less_than_200>
<total_contributions_2300>76623262</total_contributions_2300>
<net_primary_contributions>46444638.81</net_primary_contributions>
<net_general_contributions>30959481.19</net_general_contributions>
<total_refunds>2058240.92</total_refunds>
<date_coverage_from>2007-01-01</date_coverage_from>
<date_coverage_to>2008-08-31</date_coverage_to>
</candidate>
</results>
</result_set>
Sponging Freebase
Using OpenLink Data Explorer
The following instructions assume you have the OpenLink Data Explorer (ODE) browser extension installed in your browser.
An HTML description of Barack Obama can be obtained directly from Freebase by pasting the following URL into your browser: http://www.freebase.com/view/en/barack_obama
To view Network Resource Data being fetched from this page, select 'Linked Data Sources' from the browser's 'View' menu. An OpenLink Data Explorer interface will load in a new tab.
Clicking on the 'Barack Obama' link under the 'Person' category displayed by ODE retrieves RDF data using the Freebase cartridge. Click the 'down arrow' adjacent to the 'Barack Obama' link to explore the retrieved data.
Assuming your Virtuoso instance is running on port 8890 on localhost, the list of data caches displayed by ODE should include: http://localhost:8890/about/rdf/http://www.freebase.com/view/en/barack_obama#this
The information displayed in the rest of the page relates to the entity instance identified by this URI. The prefix http://localhost:8890/about/rdf prepended to the original URI indicates that the Sponger Proxy Service has been invoked. The Sponger creates an associated entity instance (identified by the above URI with the #this suffix) which holds fetched information about the original entity.
Using the Command Line
As an alternative to ODE, you can perform Network Resource Fetch from the command line with the command:
curl -H "Accept: text/xml" "http://localhost:8890/about/rdf/http://www.freebase.com/view/en/barack_obama"
To view the results, you can use Conductor's browser-based SPARQL interface (e.g. http://localhost:8890/sparql) to query the resulting graph generated by the Sponger, http://www.freebase.com/view/en/barack_obama.
Installing the Meta-Cartridge
To register the meta-cartridge, a procedure similar to the following can be used:
create procedure INSTALL_RDF_LOAD_NYTCF ()
{
-- delete any previous NYTCF cartridge installed as a primary cartridge
delete from SYS_RDF_MAPPERS where RM_HOOK = 'DB.DBA.RDF_LOAD_NYTCF';
-- register in the meta-cartridge post-processing chain
insert soft DB.DBA.RDF_META_CARTRIDGES (MC_PATTERN, MC_TYPE, MC_HOOK,
MC_KEY, MC_DESC, MC_OPTIONS)
values (
'http://www.freebase.com/view/.*',
'URL', 'DB.DBA.RDF_LOAD_NYTCF', '2c1d95a62e5fxxxxx', 'Freebase NYTCF',
vector ());
};
Looking at the list of cartridges in Conductor's 'Cartridges' screen, you will see that the Freebase cartridge is configured by default to perform Network Resource Fetch of URIs which match the pattern "http://www.freebase.com/view/.*" The meta-cartridge is configured to match on the same URI pattern.
To use the Campaign Finance API, you must register and request an API key. The script above shows an invalid key. Replace it with your own key before executing the procedure.
NYTCF Meta-Cartridge Functions
The meta-cartridge function definitions are listed below. They can be executed by pasting them into Conductor's iSQL interface.
--no_c_escapes-
create procedure DB.DBA.RDF_NYTCF_LOOKUP(
in candidate_id any, -- id of candidate
in graph_iri varchar, -- graph into which the campaign finance triples should be loaded
in api_key varchar -- NYT finance API key
)
{
declare version, campaign_type, year any;
declare nyt_url, hdr, tmp any;
declare xt, xd any;
-- Common parameters - The NYT API only supports the following values at present:
version := 'v2';
campaign_type := 'president';
year := '2008';
-- Candidate details
nyt_url := sprintf(
'http://api.nytimes.com/svc/elections/us/%s/%s/%s/finances/candidates/%s.xml?api-key=%s',
version, campaign_type, year, candidate_id, api_key);
tmp := http_get (nyt_url, hdr);
if (hdr[0] not like 'HTTP/1._ 200 %')
signal ('22023', trim(hdr[0], '\r\n'), 'RDF_LOAD_NYTCF_LOOKUP');
xd := xtree_doc (tmp);
-- baseUri specifies what the generated RDF description is about
-- <rdf:Description rdf:about="{baseUri}">
-- Example baseUri's:
-- http://localhost:8890/about/rdf/http://www.freebase.com/view/en/barack_obama#this
-- http://localhost:8890/about/rdf/http://www.freebase.com/view/en/hillary_rodham_clinton#this
xt := DB.DBA.RDF_MAPPER_XSLT (registry_get ('_cartridges_path_') || 'xslt/nytcf2rdf.xsl', xd,
vector ('baseUri', graph_iri));
xd := serialize_to_UTF8_xml (xt);
DB.DBA.RDF_LOAD_RDFXML (xd, '', graph_iri);
};
create procedure DB.DBA.RDF_MQL_RESOURCE_IS_SENATOR (
in fb_graph_uri varchar -- URI of graph containing Freebase resource
)
{
-- Check if the resource described by Freebase is a U.S. senator.
-- Only then does it make sense to query for campaign finance data from the NYT data space.
-- To test for senators, we start by looking for two statements in the Freebase cartridge
-- output, similar to:
-- <rdf:Description
-- rdf:about="http://.../about/rdf/http://www.freebase.com/view/en/hillary_rodham_clinton#this">
-- <rdf:type rdf:resource="http://xmlns.com/foaf/0.1/Person"/>
-- <rdfs:seeAlso rdf:resource="http://en.wikipedia.org/wiki/Hillary_Rodham_Clinton"/>
-- ...
-- where the graph generated by the Sponger will be
-- <http://www.freebase.com/view/en/hillary_rodham_clinton>
--
-- To test whether a resource is a senator:
-- 1) Check whether the Freebase resource is of rdf:type foaf:Person
-- 2) Extract the person_name from the Wikipedia URI referenced by rdfs:seeAlso
-- 3) Use the extracted person_name to build a URI to DBpedia's description of the person.
-- 4) Query the DBpedia description to see if the person is of rdf:type yago:Senator110578471
declare xp, xt, tmp any;
declare sparql_ep varchar; -- SPARQL endpoint
declare qry varchar; -- SPARQL query
declare qry_uri varchar; -- query URI
declare qry_res varchar; -- query result
declare default_host varchar; -- host executing this procedure
declare dbp_resource_name varchar; -- Equivalent resource name in DBpedia
declare fb_resource_uri varchar; -- Freebase resource URI
declare exit handler for sqlstate '*' {
dbg_printf ('%s', __SQL_MESSAGE);
return 0;
};
default_host := cfg_item_value (virtuoso_ini_path(), 'URIQA', 'DefaultHost');
if (default_host is null)
{
default_host := sys_stat ('st_host_name');
if (server_http_port () <> '80')
default_host := default_host ||':'|| server_http_port ();
}
fb_resource_uri := sprintf('http://%s/about/rdf/%s#this', default_host, fb_graph_uri);
-- 1) Check whether the Freebase resource is of rdf:type foaf:Person
sparql_ep := 'http://' || default_host || '/sparql';
{
declare stat, msg varchar;
declare mdata, rset any;
qry := sprintf (
'sparql ask from <%s> where { <%s> rdf:type <http://xmlns.com/foaf/0.1/Person> }',
fb_graph_uri, fb_resource_uri);
exec (qry, stat, msg, vector(), 1, mdata, rset);
if (length(rset) = 0 or rset[0][0] <> 1)
return 0;
}
-- 2) Extract the person_name from the Wikipedia URI referenced by rdfs:seeAlso
{
declare stat, msg varchar;
declare mdata, rset any;
qry := 'sparql prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> \n';
qry := qry || sprintf ('select ?o from <%s> where { <%s> rdfs:seeAlso ?o }',
fb_graph_uri, fb_resource_uri);
exec (qry, stat, msg, vector(), 1, mdata, rset);
if (length (rset) = 0)
return 0;
tmp := cast (rset[0][0] as varchar);
tmp := sprintf_inverse (tmp, 'http://en.wikipedia.org/wiki/%s', 0);
}
if (length (tmp) <> 1)
return 0;
dbp_resource_name := tmp[0];
-- 3) Use the extracted person_name to build a URI to DBpedia's description of the person.
-- 4) Query the DBpedia description to see if the person is of rdf:type yago:Senator110578471
qry := 'prefix yago: <http://dbpedia.org/class/yago/> \n';
qry := qry || 'prefix dbp: <http://dbpedia.org/resource/> \n';
qry := qry || sprintf ('ask from <http://dbpedia.org> where {dbp:%s a yago:Senator110578471}',
dbp_resource_name);
qry_res := http_client (url=>sprintf('%s?query=%U', 'http://dbpedia.org/sparql', qry),
timeout=>30);
xt := xtree_doc (qry_res);
xp := cast (xpath_eval('/sparql/boolean/text()', xt) as varchar);
if (xp = 'false')
return 0;
return 1;
};
create procedure DB.DBA.RDF_LOAD_NYTCF (
in graph_iri varchar, in new_origin_uri varchar, in dest varchar,
inout _ret_body any, inout aq any, inout ps any, inout api_key any, inout opts any )
{
declare candidate_id, candidate_name any;
declare indx, tmp any;
declare exit handler for sqlstate '*'
{
--dbg_printf('%s', __SQL_MESSAGE);
return 0;
};
if (not DB.DBA.RDF_MQL_RESOURCE_IS_SENATOR (new_origin_uri))
return 0;
-- NYT API supports a candidate_id in one of two forms:
-- candidate_id ::= {candidate_ID} | {last_name [,first_name]}
-- first_name is optional. If included, there should be no space after the comma.
--
-- Because this meta cartridge supplies additional triples for the Freebase
-- cartridges, only the second form of candidate_id is supported.
-- i.e. We extract the candidate name, rather than a numeric
-- candidate_ID (FEC committee ID) from the Freebase URL.
--
-- It's assumed that the source URI includes the candidate's first name.
-- If it is omitted, the NYT API will return information about *all* candidates
-- with that last name - something we don't want.
indx := strstr(graph_iri, 'www.freebase.com/view/en/');
if (indx is not null)
{
-- extract candidate_id from Freebase URI
tmp := sprintf_inverse(subseq(graph_iri, indx), 'www.freebase.com/view/en/%s', 0);
if (length(tmp) <> 1)
return 0;
candidate_name := tmp[0];
}
else
{
return 0;
}
-- split candidate_name into its component parts
-- candidate_name is assumed to be firstname_[middlename_]*lastname
-- e.g. hillary_rodham_clinton (Freebase), Hillary_clinton (Wikipedia)
{
declare i, _end, len int;
declare names, tmp_name varchar;
names := vector ();
tmp_name := candidate_name;
len := length (tmp_name);
while (1)
{
_end := strchr(tmp_name, '_');
if (_end is not null)
{
names := vector_concat (names, vector(subseq(tmp_name, 0, _end)));
tmp_name := subseq(tmp_name, _end + 1);
}
else
{
names := vector_concat(names, vector(tmp_name));
goto done;
}
}
done:
if (length(names) < 2)
return 0;
-- candidate_id ::= lastname,firstname
candidate_id := sprintf('%s,%s', names[length(names)-1], names[0]);
}
DB.DBA.RDF_NYTCF_LOOKUP(candidate_id, coalesce (dest, graph_iri), api_key);
return 0;
}
NYTCF Meta-Cartridge Stylesheet
The XSLT stylesheet, nyctf2rdf.xsl, used by the meta-cartridge to transform the base Campaign Finance web service output to RDF is shown below. RDF_NYCTF_LOOKUP() assumes the stylesheet is located alongside the other stylesheets provided by the cartridges VAD in the Virtuoso WebDAV folder DAV/VAD/cartridges/xslt/meta. You should create nyctf2rdf.xsl here from the following listing. The WebDAV Browser interface in Conductor provides the easiest means to upload the stylesheet.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE xsl:stylesheet [
<!ENTITY rdf "http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<!ENTITY nyt "http://www.nytimes.com/">
]>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:vi="http://www.openlinksw.com/virtuoso/xslt/"
xmlns:rdf=""
xmlns:nyt=""
>
<xsl:output method="xml" indent="yes" />
<xsl:template match="/result_set/status">
<xsl:if test="text() = 'OK'">
<xsl:apply-templates mode="ok" select="/result_set/results/candidate"/>
</xsl:if>
</xsl:template>
<xsl:template match="candidate" mode="ok">
<rdf:Description rdf:about="{vi:proxyIRI($baseUri)}">
<nyt:candidate_name><xsl:value-of select="candidate_name"/></nyt:candidate_name>
<nyt:committee_id><xsl:value-of select="committee_id"/></nyt:committee_id>
<nyt:party><xsl:value-of select="party"/></nyt:party>
<nyt:total_receipts><xsl:value-of select="total_receipts"/></nyt:total_receipts>
<nyt:total_disbursements>
<xsl:value-of select="total_disbursements"/>
</nyt:total_disbursements>
<nyt:cash_on_hand><xsl:value-of select="cash_on_hand"/></nyt:cash_on_hand>
<nyt:net_individual_contributions>
<xsl:value-of select="net_individual_contributions"/>
</nyt:net_individual_contributions>
<nyt:net_party_contributions>
<xsl:value-of select="net_party_contributions"/>
</nyt:net_party_contributions>
<nyt:net_pac_contributions>
<xsl:value-of select="net_pac_contributions"/>
</nyt:net_pac_contributions>
<nyt:net_candidate_contributions>
<xsl:value-of select="net_candidate_contributions"/>
</nyt:net_candidate_contributions>
<nyt:federal_funds><xsl:value-of select="federal_funds"/></nyt:federal_funds>
<nyt:total_contributions_less_than_200>
<xsl:value-of select="total_contributions_less_than_200"/>
</nyt:total_contributions_less_than_200>
<nyt:total_contributions_2300>
<xsl:value-of select="total_contributions_2300"/>
</nyt:total_contributions_2300>
<nyt:net_primary_contributions>
<xsl:value-of select="net_primary_contributions"/>
</nyt:net_primary_contributions>
<nyt:net_general_contributions>
<xsl:value-of select="net_general_contributions"/>
</nyt:net_general_contributions>
<nyt:total_refunds><xsl:value-of select="total_refunds"/></nyt:total_refunds>
<nyt:date_coverage_from rdf:datatype="date">
<xsl:value-of select="date_coverage_from"/>
</nyt:date_coverage_from>
<nyt:date_coverage_to rdf:datatype="date">
<xsl:value-of select="date_coverage_to"/>
</nyt:date_coverage_to>
</rdf:Description>
</xsl:template>
<xsl:template match="text()|@*"/>
</xsl:stylesheet>
The stylesheet uses the prefix nyt: (http://www.nytimes.com) for the predicates of the augmenting triples. This has been used purely for illustration - you may prefer to define your own ontology for RDF data derived from New York Times APIs.
Testing the Meta-Cartridge
After creating the required Virtuoso/PL functions and installing the stylesheet, you should be able to test the meta-cartridge by sponging a Freebase page as described earlier using ODE or the command line. For instance:
- http://www.freebase.com/view/en/barack_obama , or
- http://www.freebase.com/view/en/hillary_rodham_clinton
You should see campaign finance data added to the graph created by the Sponger in the form of triples with predicates starting http://www.nytimes.com/xxx, e.g. http://www.nytimes.com/net_primary_contribution.
How The Meta-Cartridge Works
The comments in the meta-cartridge code detail how the cartridge works. In brief:
Given the URI of the graph being created by the Freebase cartridge, RDF_MQL_RESOURCE_IS_SENATOR checks if the resource described by Freebase is a U.S. senator. Only then does it make sense to query for campaign finance data from the NYTCF data space.
To test for senators, the procedure starts by looking for two statements in the Freebase cartridge output similar to:
<rdf:Description rdf:about="http://localhost:8890/about/rdf/http://www.freebase.com/view/en/barack_obama#this"> <rdf:type rdf:resource="http://xmlns.com/foaf/0.1/Person"/> <rdfs:seeAlso rdf:resource="http://en.wikipedia.org/wiki/Barack_Obama"/> ...
where the graph generated by the Sponger will be
<http://www.freebase.com/view/en/barack_obama>
To test whether a resource is a senator, RDF_MQL_RESOURCE_IS_SENATOR
- Checks whether the Freebase resource is of rdf:type foaf:Person
- Extracts the person's name from the Wikipedia URI referenced by rdfs:seeAlso
- Uses the extracted name to build a URI to DBpedia's description of the person.
- Queries the DBpedia description to see if the person is of rdf:type yago:Senator110578471 (YAGO is a semantic knowledge base which provides a core set of concepts which in turn are used by DBpedia.)
Only if this is the case is the RDF_NYTCF_LOOKUP routine called to query for and return campaign finance data for the candidate. The form of the query and the resulting XML output from the Campaign Finance service were presented earlier.