Deploying Linked Data - Part 1: Introduction
Deploying Linked Data - TOCSection Contents
- Introduction
Introduction
The current ubiquitous World Wide Web (Web) is a mesh of "Linked Documents" connected by hypertext links. Each link serves the single purpose of connecting one document to another, and that's it. This widely understood and accepted Web interaction pattern is facilitated by a dual resource identification/location facility called a Uniform Resource Locator (URL) and a messaging protocol known as the HyperText Transfer Protocol (HTTP).
The popularity of the current "Web of Documents" (or "Document Web") sometimes obscures the fact that from the outset Tim Berners-Lee envisaged the Web as an information space connecting disparate data spaces as part of a granular "Web of Linked Data Items". In this more granular form of the Web, each item of data (a datum) is uniquely identified by a resolvable identifier called an HTTP URI and applicability extends to real-world objects; basically a scheme similar to Object or Entity Identity in the distributed database management technology realm.
Ultimately, evolving an erstwhile coarse and inherently opaque Web of "Linked Documents" into a fine grained mesh of "Linked Data", is how the Web ultimately intersects with the original vision of: hyper-orthogonality across disparate data sources, long espoused by Ted Nelson, the father of hypermedia.
In this document we cover the use of Virtuoso as a Linked Data Deployment platform for injecting Linked Data meshes into the broader Web.
What's The Current Problem?
The existing Document Web comprises a linked mesh of information-bearing documents, where we use the term "information" to mean "data in a particular context" and where, unfortunately, the context in question is frequently inherently subjective. The aim of Linked Data is to free information from its contextual confines and in so doing enable access and linking via the Web to objective raw data.What is Linked Data?
"Linked Data" is the title of a Web Design Issues Note by Berners-Lee that describes a best-practice recipe for injecting data into the Web as part of a broader effort to evolve the current Web of interlinked documents to a Web of Linked Data. The principles he outlined are as follows (paraphrased):
- Name things (real or abstract) in your universe-of-discourse (data spaces) using URIs.
- Use HTTP to construct URIs so that people can discover and explore your data via the Web.
- Expose useful information via your URIs
- Enhance your URIs by adding links to other data on the Web using their URIs thereby enhancing the link density and richness of the Web.
What Does The Linked Data Meme Enable?
The underpinnings of Linked Data are provided by the Resource Description Framework (RDF), a framework for describing Web addressable resources through associated metadata (structured data about data). RDF (and supporting layers like RDFS and OWL) support the Entity-Attribute-Value (aka Subject-Predicate-Object) + Classes & Relationships metadata model (EAV/CR). A model that's been with us since the inception of modern computing, long before the Web.
By following the Linked Data guidelines and endowing subjects, their attributes, and optionally attribute values, with HTTP URIs when producing EAV/CR model-based metadata, the result is a Web architecture friendly metadata scheme that makes possible a new level of link abstraction on the Web in which data item to data item "hyperdata" links predominate over document to document links. Ultimately, the Linked Data meme provides a vehicle for realizing the full capabilities of the Web as a platform for open data identification, data definition, data access, storage, representation, presentation, and integration.
Deployment Challenges
The succinctness of the Linked Data principles summarised above hides an easily missed subtlety regarding the duality of HTTP URIs, in that they serve two essential roles in Linked Data deployment - they both identify Linked Data entities and provide access to Linked Data entity descriptions, i.e. entity metadata. Our everyday use of the Document Web unfortunately conflates identity and access, whereas in the Data Web these notions are quite distinct.
What do we mean by identity? People, places, ideas, music, and other real world objects (RWOs) possess "identity", that is a collection of characteristics that distinguish them from another entity. Associated with this abstraction can be a label used as a unique identifier. In the case of Linked Data, we use URIs.
Accessing an entity is in effect to request information about it. The information returned comprises metadata describing the real world object. Access does not return the object itself (clearly this will be impossible if the object is a person!) but a description of it. Several descriptions of a object may exist, each offering a different perspective or representation format. Thus when you access, or de-reference, a URI, you request a description of an entity's characteristics as a Web-accessible document (aka an information resource).
Exploiting HTTP URI Duality
Although the term URI is often used unadorned in the context of Linked Data, the need to support both identity and access requires that Linked Data URIs be HTTP URIs, which provide both entity identity and access to the entity's metadata. A URI may be classed as a locator (URL) or a name (URN). When a URN, a URI need only identify a resource. The resource may be abstract and consequently not dereferenceable. In the Linked Data realm, by limiting URIs to the HTTP scheme, the URIs become dereferenceable URLs, specifying both the identity and location of Web information resources. Moreover, HTTPs content negotiation mechanism provides a means for an HTTP client and server to negotiate the preferred representation at request time, for example to select between (X)HTML+RDFa, JSON, XML, RDF/XML, N3, Turtle, Trix and other possible representations.
The dual nature of HTTP URIs and their ability to furnish:
- RWO identifiers/names
- RWO metadata document locators
- Negotiable representations of the located metadata document
provides a powerful abstraction layer for platform independent data access not possible with the current Document Web.
Real-World Object Referencing
Clearly the Linked Data Web and the Document Web are two dimensions of the same Web separated by a common element, the URI. In the Document Web, URIs are normally of the URL (rather than URN) variety, and identify "physical" Web documents (information resources) by their location, making no distinction between identity and access. In order for Linked Data style real-world data object referencing to work on the existing Web, all resource URIs need to be HTTP-based. In addition, on the deployment side, a Linked Data deployment platform needs to support:
- separation of identity from representation within the context of HTTP protocol mechanics
- dynamic generation of proxy information resources that convey descriptions of a real-world object when its HTTP-based URI is dereferenced
- transparent content negotiation that involves quality of service algorithms instigatable on the client and/or server sides
- URL re-writing and query association
We explore how these challenges can be met below.
Resource Identity
In the previous section we established the difference between Web resource URLs and real-world object URIs as object identification and naming mechanisms. In the sections that follow, we are going to explore different naming schemes and rules for establishing real-world object URIs in the Linked Data Web realm.
Hash & Slash based URIs
Hash URIs
One convention adopted by some Linked Data practitioners is the so-called 'hash URI' scheme where a URI is combined with a fragment identifier ('#' and an identification character sequence) to construct a natural (human readable) identifier. e.g.<http://demo.openlinksw.com/Northwind/Customer/ALFKI#this> where the fragment identifier component of the URI enables use of the Web resource at <http://demo.openlinksw.com/Northwind/Customer/ALFKI> as a proxy for conveying a descriptive representation of real-world object <http://demo.openlinksw.com/Northwind/Customer/ALFKI#this>.
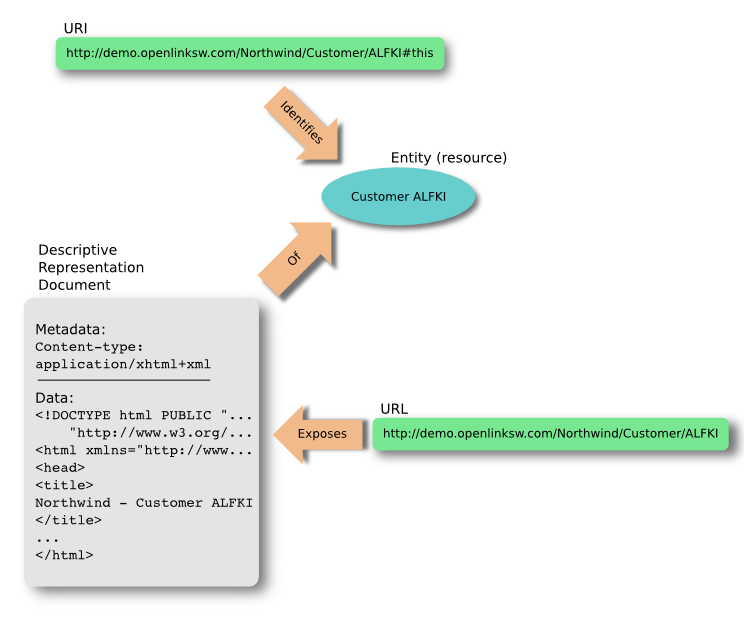
URI semantics - separating identification & naming from representation
The fundamental advantage of this scheme comes down to the fact that resource descriptions are obtained via a single network hop. On the other hand it carries the disadvantage of being representation format specific with regards to the proxy resource used to convey descriptive representation of a given entity (or resource). For instance, you can only use this approach for RDF or HTML representations but not both within the context of the "single hop" benefit, so each additional descriptive representation will require a 30X redirect as examples later in this document with unveil.
Slash URIs
An alternative approach is a slash based scheme in which the resulting identifier looks -- for all intents and purposes -- like a typical Web resource URL, but at resource description request time the deployment server employs HTTP redirection to guide clients towards representation specific Web resource URLs that convey resource descriptions. Examples include:
-
<http://demo.openlinksw.com/Northwind/Customer/ALFKI/id>: the URI uniquely identifies an entity (real-world data object) -
<http://demo.openlinksw.com/Northwind/Customer/ALFKI/page>: the URI identifies an HTML-based representation of the entity being described -
<http://demo.openlinksw.com/Northwind/Customer/ALFKI/data>: the URI identifies an RDF-based representation of the entity being described
The fundamental advantage of this approach is that the URI and its associated resource description URLs are clearly discernible to a human observer. On the other hand it carries the disadvantage of additional network hops via mandatory 30X redirection from the real-world object URI to associated representation specific Web resource URLs conveying its description.
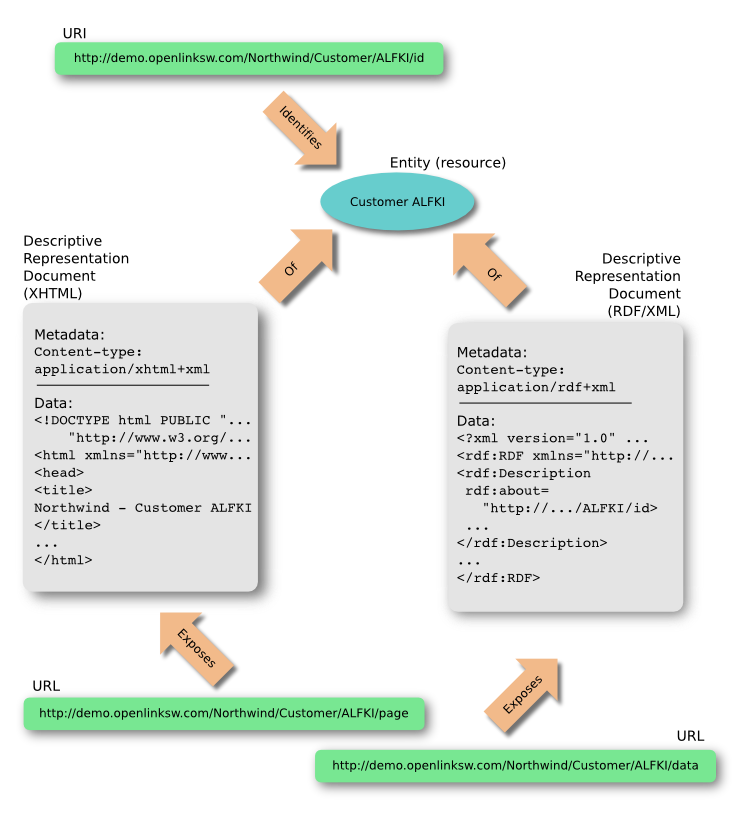
URI semantics - separating identification & naming from representation
Resolution of the Deployment Challenge
As covered in the prior section, HTTP based URIs provide an ingenious mechanism for separating the identity of a real-world object from the representation of its description. The sections that follow cover some of the mechanics of content negotiation and the combined use of content negotiation, re-write rules, and the SPARQL query language to deliver a platform independent mechanism for deploying Linked Data into the Web.
Content Negotiation
Content negotiation is an intrinsic HTTP protocol mechanism that makes it possible to serve different representations of a physical resource, or descriptions of a real-world object, from a single URI, such that software agents can choose which representation best fits their capabilities.A browser or any other HTTP-based web application indicates its resource representation preferences by packaging these preferences in the " Accept* " headers of each HTTP request.
For example, a browser could send the following HTTP request to indicate that it wants an HTML or XHTML based representation of the resource <http://www.openlinksw.com/whitepapers/data_management> in English or French:
GET /whitepapers/data_management HTTP/1.1 Host: www.openlinksw.com Accept: text/html, application/xhtml+xml Accept-Language: en, fr
Here, the HTTP Accept: header sent by the browser indicates the MIME types it wants ( text/html or application/xhtml+xml , for HTML and XHTML, respectively).
An RDF browser, in contrast, might stipulate a Content Type of application/rdf+xml or application/rdf+n3 indicating RDF/XML or N3 resource description representations respectively.
Rather than returning the content in the required format directly, Web servers often implement content negotiation by redirecting to an information resource URL associated with a physical resource that has been constructed in conformance with the content type of the request. For example, a server might respond with:
HTTP/1.1 302 Found Location: http://www.openlinksw.com/whitepapers/data_management.en.html
The redirect is indicated by the HTTP status code 302 (Found) .
The client would then send another HTTP request for the new URL.
HTTP defines a number of 3xx status codes, all of which indicate the client is being redirected.
Instead of 302 , servers may also use 303 (See Other) to indicate the response to the request can be found at another location (which is also provided, via the " Location: " response header).
HttpRange-14 Recommendations
The problem of URI/resource-type interpretation was originally addressed by the W3C Technical Architecture Group (TAG) around 2005 and was known as theHttpRange-14 issue.
After a good deal of deliberation, the TAG proposed the guidelines below on the information that can be inferred from HTTP protocol response codes received when dereferencing a URI:| HTTP Response Code | Material Returned | Inference |
200 (success)
|
A resource representation and its location | A Web information resource has been located in the desired representation. |
303 (see other)
|
A resource location | A redirection to the location of an associated Web information resource in a desired representation. |
4XX or 5XX (error)
|
Nothing | No Web information resource or resource location is discernible from the resource and representation combination used in the message. |
Content Negotiation & Linked Data Deployment
Content Negotiation with Hash URI Based Data Object Naming Scheme
We give some examples of content negotiation using a hash-based URI scheme below.
The examples assume that the '#this' suffix of a hash URI is not lost en-route to the Linked Data server, but this cannot be guaranteed.
(From the perspective of Linked Data servers, the URIs http://demo.openlinksw.com/Northwind/Customer/ALFKI and http://demo.openlinksw.com/Northwind/Customer/ALFKI#this are identical, because nothing following the fragment identifier leaves the Web Client realm, due to the fact that the Web Client expects to process the '#this' suffix locally, post resource retrieval.) > We give some examples of content negotiation using a hash-based URI scheme below.
The examples assume that the '#this' suffix of a hash URI is not lost en-route to the Linked Data server, but this cannot be guaranteed.
(From the perspective of Linked Data servers, the URIs http://demo.openlinksw.com/Northwind/Customer/ALFKI and http://demo.openlinksw.com/Northwind/Customer/ALFKI#this are identical, because nothing following the fragment identifier leaves the Web Client realm, due to the fact that the Web Client expects to process the '#this' suffix locally, post resource retrieval.)
Returning to our earlier example URIs, http://demo.openlinksw.com/Northwind/Customer/ALFKI and http://demo.openlinksw.com/Northwind/Customer/ALFKI#this, we can construct a decision table that demonstrates how a deployer of Linked Data would leverage content negotiation en route to alleviating the previously outlined Data Access and Data Reference challenges.
Example 1: Static descriptions of a Data Object
The first example assumes the simplest case of there being static HTML and RDF documents available to provide HTML and RDF representations of the customer entity ALFKI.| URI | URI Type | Requested Representation (X)HTML | Requested Representation RDF |
http://demo.openlinksw.com/Northwind/Customer/ALFKI
|
Web Resource URL | 200 (OK) - if an (X)HTML information resource (document) exists on the serveror 404 - if (X)HTML document isn't available on serveror 406 - if descriptive representation in this format isn't applicable |
200 (OK) - if an RDF information resource exists on the server. |
http://demo.openlinksw.com/Northwind/Customer/ALFKI#this
|
Hash based HTTP specific URN | 303 (Redirect) - to an associated (X)HTML document that describes entity <http://demo.openlinksw.com/Northwind/Customer/ALFKI#this>,or 404 - if entity description isn't dereferenceable from this server |
200 (OK) - Return RDF based information resource: <http://demo.openlinksw.com/Northwind/Customer/ALFKI> that describes entity <http://demo.openlinksw.com/Northwind/Customer/ALFKI#this> using N3, Turtle, RDF/XML etc.
|
Example 2: Dynamically derived descriptions of a Data Object using a SPARQL DESCRIBE
The next example illustrates the use of a SPARQL DESCRIBE query to provide an RDF rendering of the entity being dereferenced by the client.
If only a few entities need to be described in RDF, and if we lacked an RDF quad store, we could legitimately provide these descriptions in the form of RDF documents, to which we redirect when the client requests RDF/XML.
Obviously when the entities are described in a quad store, the sensible approach is to return an RDF description directly from the store by redirecting, via URL rewriting, to the store's SPARQL endpoint to request a description rendered by either a CONSTRUCT or DESCRIBE query.
The general forms are:
-
DESCRIBE <entity-uri> FROM <graph-uri> -
CONSTRUCT { <entity-uri> ?p ?o } FROM <graph-uri> WHERE { <entity-uri> ?p ?o }
Note: Both return an RDF graph.
However the DESCRIBE query feature is 'unconstrained'.
The description returned in not prescribed by the SPARQL specification and is determined by the SPARQL query processor.
(Virtuoso allows applications to tailor the description to their individual needs through the proprietary SPARQL define sql:describe-mode which is used to specify custom procedures for generating the DESCRIBE output.)
So, an RDF representation of entity ALFKI is provided by the result of a SPARQL DESCRIBE query. A dynamic HTML representation of ALFKI is obtained by rendering the RDF description (again extracted by a SPARQL DESCRIBE) as HTML. OpenLink uses just such an approach, using a presentation rendering template (description.vsp - described later) to render the base RDF description as HTML.
| URI | URI Interpretation | Requested Representation (X)HTML | Requested Representation RDF |
http://demo.openlinksw.com/Northwind/Customer/ALFKI
|
Web Resource URL | 200 (OK) - if an (X)HTML information resource (document) exists on the server or 404 - if (X)HTML document isn't available on server or 406 - if descriptive representation in this format isn't applicable |
200 (OK) - if an RDF information resource exists on the server.
|
http://demo.openlinksw.com/Northwind/Customer/ALFKI#this |
Hash based HTTP specific URN | 303 (Redirect) - to an associated (X)HTML document that describes entity: <http://demo.openlinksw.com/Northwind/Customer/ALFKI#this> or 404 - if an entity description isn't dereferenceable from this server.
|
200 (OK) - Return RDF based information resource: <http://demo.openlinksw.com/Northwind/Customer/ALFKI> that describes entity: <http://demo.openlinksw.com/Northwind/Customer/ALFKI>#this; using N3, Turtle, RDF/XML etc.
You can also use a SPARQL DESCRIBE URL to deliver the RDF based description but the provenance of the description potentially becomes obscured. |
In Example 1, when an HTML representation of http://demo.openlinksw.com/Northwind/Customer/ALFKI#this is requested, the client is re-directed (through a 303 response code) to the HTML document identified by http://demo.openlinksw.com/Northwind/Customer/ALFKI. In Example 2, the same result is achieved by different means. Again a request for an HTML representation of http://demo.openlinksw.com/Northwind/Customer/ALFKI#this results in the (dynamically derived) HTML document associated with http://demo.openlinksw.com/Northwind/Customer/ALFKI being returned. In this case though, an internal(rather than external 303) redirect is used, consequently the response code is 200.

It is also important to note that deploying Linked Data in this way is quite similar to using HTTP-based URLs as report-writer-style document identifiers. The key difference is that the data in the report is self-describing and granular; i.e. each entity in the page has an HTTP-based URI and the semantics of the relationship between the report and the associated entities can be explicitly expressed. Thus, the entity "ALFKI" is first exposed as the value of the "foaf:primaryTopic" property and then, when it's de-referenced, the associated description is returned via a document that is identified via a URL containing an escaped form of "#" (%23) which simply negates the ambiguity that fragment identifiers introduced when dealing with this the hash URI scheme i.e. the fragment ID is discarded at HTTP GET time by user agents since its sole use is for local processing.
Content Negotiation with a Slash URI Based Data Object Naming Scheme
Using the slash URI naming scheme outlined above, the server responses to possible URI / content-type request combinations might be as follows:| URI | Requested Representation (X)HTML | Requested Representation RDF |
<http://demo.openlinksw.com/Northwind/Customer/ALFKI/id> |
303 (Redirect) to (X)HTML information resource at <http://demo.openlinksw.com/Northwind/Customer/ALFKI/page> |
303 (Redirect) to RDF information resource at <http://demo.openlinksw.com/Northwind/Customer/ALFKI/data> |
<http://demo.openlinksw.com/Northwind/Customer/ALFKI/page> |
200 (OK) - Return an (X)HTML information resource that describes entity <http://demo.openlinksw.com/Northwind/Customer/ALFKI/id> |
406 (Not available in this representation)
Note: The <head> section of resource <http://demo.openlinksw.com/Northwind/Customer/ALFKI/page> could be used to point to <http://demo.openlinksw.com/Northwind/Customer/ALFKI/data> via <link> using the @rel property.
You can also use RDFa within <http://demo.openlinksw.com/Northwind/Customer/ALFKI/page> to establish a link with <http://demo.openlinksw.com/Northwind/Customer/ALFKI/data> |
<http://demo.openlinksw.com/Northwind/Customer/ALFKI/data> |
406 (Not available in this representation) Note: The triples in the RDF information resource can be used to direct user agents to the resource <http://demo.openlinksw.com/Northwind/Customer/ALFKI/page> |
200 (OK) - Return an RDF information resource describing entity <http://demo.openlinksw.com/Northwind/Customer/ALFKI/id> using N3, Turtle, RDF/XML etc.
|
Again, if the base description data was being retrieved dynamically from a quad store, our table might become:
| URI | Requested Representation (X)HTML | Requested Representation RDF |
<http://demo.openlinksw.com/Northwind/Customer/ALFKI/id> |
303 (Redirect) to (X)HTML information resource at <http://demo.openlinksw.com/Northwind/Customer/ALFKI/page> |
303 (Redirect) to RDF information resource at <http://demo.openlinksw.com/Northwind/Customer/ALFKI/data> |
<http://demo.openlinksw.com/Northwind/Customer/ALFKI/page> |
200 (OK) - Return an (X)HTML information resource that describes entity <http://demo.openlinksw.com/Northwind/Customer/ALFKI/id> |
406 (Not available in this representation)
Note: The <head> section of resource <http://demo.openlinksw.com/Northwind/Customer/ALFKI/page> could be used to point to <http://demo.openlinksw.com/Northwind/Customer/ALFKI/data> via <link> using the @rel property.
You can also use RDFa within <http://demo.openlinksw.com/Northwind/Customer/ALFKI/page> to establish a link with <http://demo.openlinksw.com/Northwind/Customer/ALFKI/data> |
<http://demo.openlinksw.com/Northwind/Customer/ALFKI/data> |
406 (Not available in this representation) Note: The triples in the RDF information resource can be used to direct user agents to the resource <http://demo.openlinksw.com/Northwind/Customer/ALFKI/page> |
200 (OK) - Return an RDF information resource describing entity <http://demo.openlinksw.com/Northwind/Customer/ALFKI/id> using N3, Turtle, RDF/XML etc.
You can also use a SPARQL DESCRIBE URL to deliver the RDF based description of the entity <http://demo.openlinksw.com/Northwind/Customer/ALFKI/id> but the provenance of the description potentially becomes obscured.
|
URL Rewriting
URL rewriting is the act of modifying a requested source URL prior to the final processing of that URL by a Web Server.The ability to rewrite URLs may be desirable for many reasons that include:
- Changing Web information resource URLs on the a Web Server without breaking existing bookmarks held in User Agents (e.g., Web browsers)
- URL compaction where shorter URLs may be constructed on a conditional basis for specific User Agents (e.g., Email clients)
- Construction of search engine friendly URLs that enable richer indexing since most search engines cannot process parameterized URLs effectively.
Using URL Rewriting to Solve Linked Data Deployment Challenges
In the previous section we demonstrated how content negotiation and HTTP response messages could be used to address the data access issues arising from the use of URIs associated with resource identity and representation.
We determined earlier that URI naming schemes don't fully resolve the challenges associated with referencing data.
To reiterate, this is demonstrated by the fact that the URIs http://demo.openlinksw.com/Northwind/Customer/ALFKI and http://demo.openlinksw.com/Northwind/Customer/ALFKI#this both appear as http://demo.openlinksw.com/Northwind/Customer/ALFKI to the Web Server, since data following the fragment identifier "#" never makes it that far.
The only way to address data referencing is by pre-processing source URIs (e.g., via regular expression or sprintf substitutions) as part of a URL rewriting processing pipeline.
The pipeline process has to take the form of a set of rules that cater for elements such as HTTP Accept headers, HTTP response codes, HTTP response headers, and rule processing order.
An example of such a pipeline is depicted in the table below.
| Source URI (Regular Expression Pattern) | HTTP Accept Headers (Regular Expression) | HTTP Response Code | HTTP Response Headers | Rule Processing Order |
/Northwind/Customer/([^#]*)
|
None (i.e. default) | 200 or 303 responses depending on the user agent default or server side quality of service rules via Transparent Content Negotiation. |
None | Normal (order irrelevant) |
/Northwind/Customer/([^#]*)
|
(text/rdf.n3) | (application/rdf.xml) |
303 redirect to a URL which DESCRIBEs the entity identified by the URI. |
None | Normal (order irrelevant) |
/Northwind/Customer/([^#]*)
|
(text/html) | (application/xhtml.xml) |
406 (Not acceptable) , or if an (X)HTML document describing the entity exists 200 (OK) & return the document, or 303 redirect to a URL which can render the requested representation. |
For 406:Vary: negotiate, accept Alternates: {"ALFKI" 0.9 {type application/rdf+xml}}
|
Normal (order irrelevant) |
The flow between client and server, based on the above decision table is shown in the next figure.

Client/server content negotiation for an RDF representation
The source URI patterns refer to virtual or physical directories at http://demo.openlinksw.com/.
Rules can be placed at the head or tail of the pipeline, or applied in the order they are declared, by specifying a Rule Processing Order of First, Last, or Normal, respectively.
The decision as to which representation to return for URI http://demo.openlinksw.com/Northwind/Customer/ALFKI is based on the MIME type(s) specified in any Accept header accompanying the request.
In the case of the last rule, the Alternates response header applies only to response code 406 .
406 would be returned if there were no (X)HTML representation available for the requested resource.
In the example shown, an alternative representation is available in RDF/XML.
When applied to matching HTTP requests, the last two rules might generate responses similar to those below.
In the first cURL exchange, the target Virtuoso server redirects to a SPARQL endpoint that retrieves an RDF/XML representation of the requested entity:
$ curl -I -H "Accept: application/rdf+xml" http://demo.openlinksw.com/Northwind/Customer/ALFKI
HTTP/1.1 303 See Other
Server: Virtuoso/05.00.3016 (Solaris) x86_64-sun-solaris2.10-64 PHP5
Connection: close
Content-Type: text/html; charset=ISO-8859-1
Date: Mon, 16 Jul 2007 22:40:03 GMT
Accept-Ranges: bytes
Location: /sparql?query=CONSTRUCT+{+%3Chttp%3A//demo.openlinksw.com/Northwind/Customer/ALFKI%23this%3E+%3Fp+%3Fo+}
+FROM+%3Chttp%3A//demo.openlinksw.com/Northwind%3E
+WHERE+{+%3Chttp%3A//demo.openlinksw.com/Northwind/Customer/ALFKI%23this%3E+%3Fp+%3Fo+}&format=application/rdf%2Bxml
Content-Length: 0
In the second cURL exchange, the target Virtuoso server indicates that there is no resource to deliver in the requested representation.
It provides hints in the form of an alternate resource representation and URI that may be appropriate, i.e., an RDF/XML representation of the requested entity:
$ curl -I -H "Accept: text/html" http://demo.openlinksw.com/Northwind/Customer/ALFKI
HTTP/1.1 406 Not Acceptable
Server: Virtuoso/05.00.3016 (Solaris) x86_64-sun-solaris2.10-64 PHP5
Connection: close
Content-Type: text/html; charset=ISO-8859-1
Date: Mon, 16 Jul 2007 22:40:23 GMT
Accept-Ranges: bytes
Vary: negotiate,accept
Alternates: {"ALFKI" 0.9 {type application/rdf+xml}}
Content-Length: 0
Back to Deploying Linked Data Guide | Next: Deploying Linked Data Using Virtuoso