Setting up a Content Crawler Job to retrieve Semantic Sitemaps
The following guide describes how to set up crawler job for getting Semantic Sitemap's content -- a variation of standard sitemap:
- Go to Conductor UI. For ex. at http://localhost:8890/conductor .
- Enter dba credentials.
- Go to "Web Application Server".
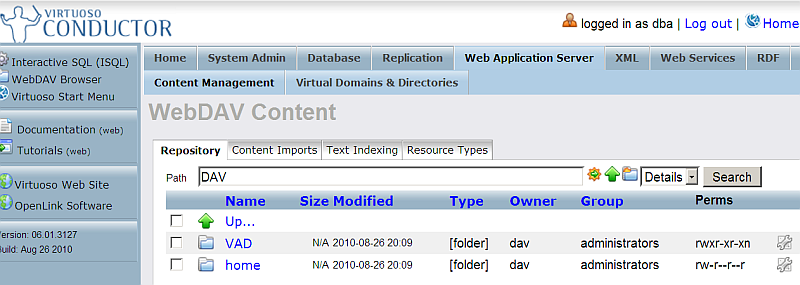
- Go to "Content Imports".
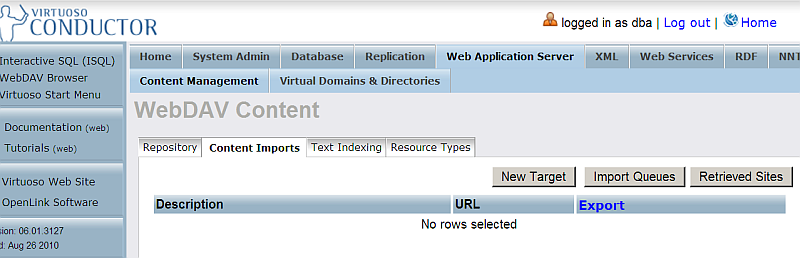
- Click "New Target".
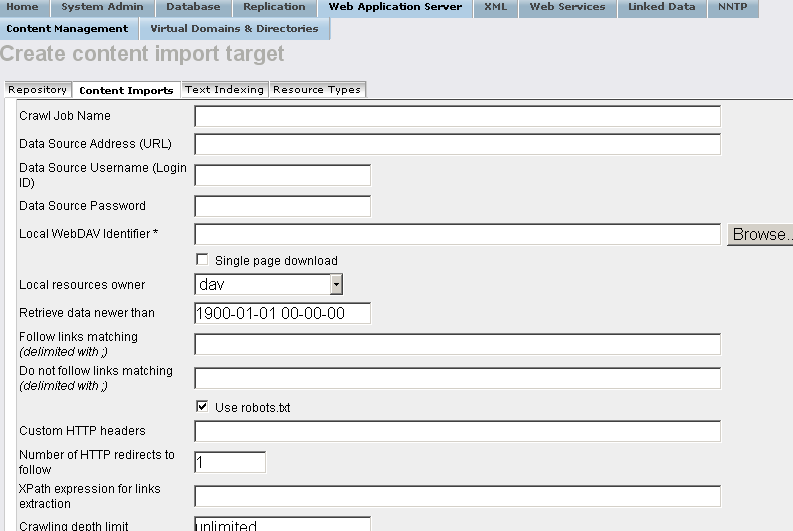
- In the shown form:
- Enter for "Crawl Job Name":
Semantic Web Sitemap Example
- Enter for "Data Source Address (URL)":
http://www.connexfilter.com/sitemap_en.xml
- Enter the location in the Virtuoso WebDAV repository the crawled should stored in the "Local WebDAV Identifier " text-box, for example, if user demo is available, then:
/DAV/home/demo/semantic_sitemap/
- Choose the "Local resources owner" for the collection from the list box available, for ex: user demo.
- Hatch "Semantic Web Crawling":
- Note: when you select this option, you can either:
- Leave the Store Function and Extract Function empty - in this case the system Store and Extract functions will be used for the Semantic Web Crawling Process, or:
- You can select your own Store and Extract Functions. View an example of these functions.
- Note: when you select this option, you can either:
- Hatch "Accept RDF"
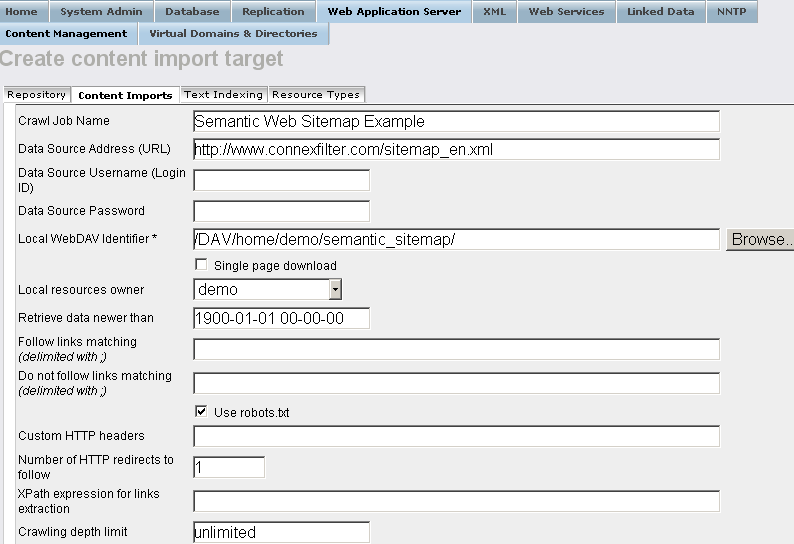
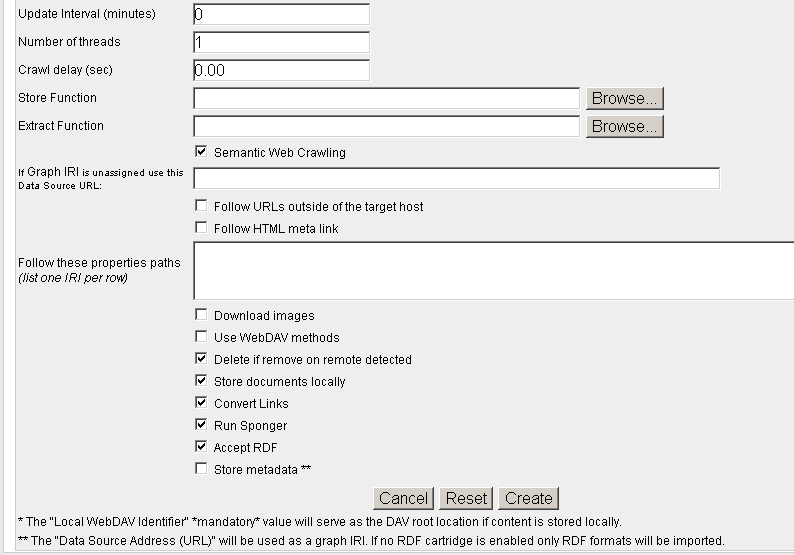
- Optionally you can hatch "Store metadata *" and specify which RDF Cartridges to be included from the Sponger:

- Enter for "Crawl Job Name":
- Click the button "Create".
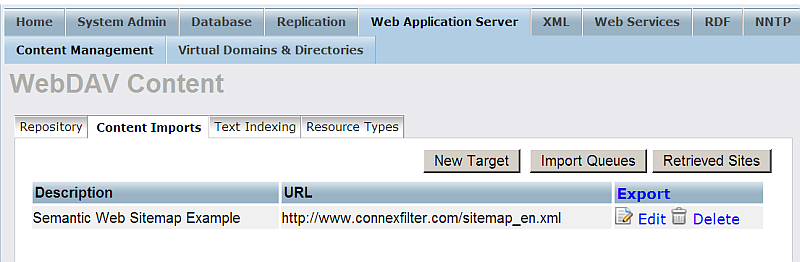
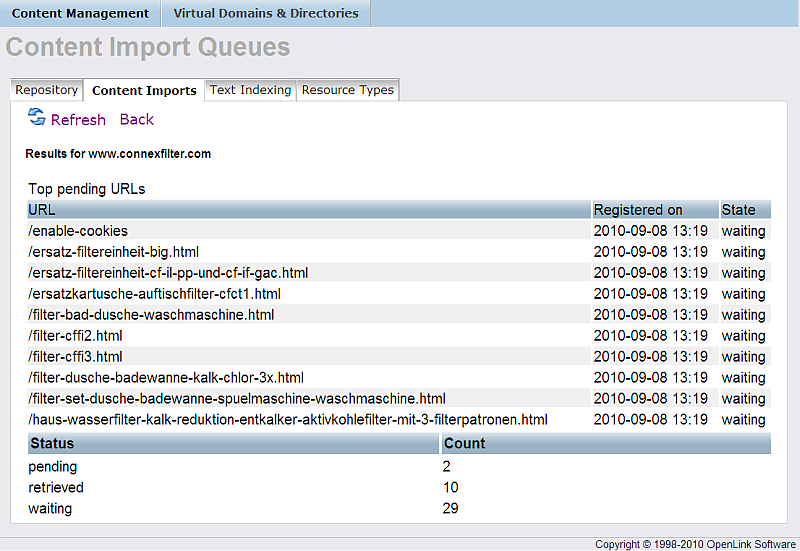
- Click "Import Queues".

- For "Robot target" with label "Semantic Web Sitemap Example" click "Run".
- As result should be shown the number of the pages retrieved.
- Check the retrieved RDF data from your Virtuoso instance SPARQL endpoint http://cname:port/sparql with the following query selecting all the retrieved graphs for ex:
SELECT ?g FROM <http://localhost:8890/> WHERE { graph ?g { ?s ?p ?o } . FILTER ( ?g LIKE <http://www.connexfilter.com/%> ) }

Related
- Setting up Crawler Jobs Guide using Conductor
- Setting up a Content Crawler Job to Add RDF Data to the Quad Store
- Setting up a Content Crawler Job to Retrieve Sitemaps (where the source includes RDFa)
- Setting up a Content Crawler Job to Retrieve Content from Specific Directories
- Setting up a Content Crawler Job to Retrieve Content from SPARQL endpoint