Exploiting Virtuoso's Anytime Query Feature
What?
Virtuoso has a native mechanism for providing query results within a configurable time-frame.Why?
This feature is called "Anytime Query" and its vital to any practical DBMS related offering (especially on the World Wide Web) that supports query access from an unpredictable number of clients performing a variety of queries.How?
This functionality is available via the default HTML based SPARQL Query Editor page that accompanies all Virtuoso instances. It is also available via a URI parameter (&timeout={time in milliseconds}) as part of Virtuoso's SPARQL Protocol implementation.Sample Scenario
The following scenario demonstrates how to manage anytime SPARQL query execution using the timeout parameter at a Virtuoso SPARQL Endpoint.
Suppose a simple query:
SELECT DISTINCT ?p
WHERE
{
?s ?p ?o
}
LIMIT 100
Suppose the query execution fails against Virtuoso endpoint due to running out of execution time as set in virtuoso.ini configuration file.
This is basically a table scan, since it has to go through each quad and create a HASH of unique P it sees.
After that is done, it will return the first 100 values of P from this hash.
Next we will use SQL translation and explain() of the query:
SQL> SET sparql_translate ON;
SQL> SELECT DISTINCT ?p WHERE { ?s ?p ?o } LIMIT 100;
SPARQL_TO_SQL_TEXT
VARCHAR
_______________________________________________________________________________
SELECT __ro2sq ("s_2_0_rbc"."p") AS "p" FROM (SELECT DISTINCT TOP
100 __id2i ( "s_2_1-t0"."P" ) AS "p"
FROM DB.DBA.RDF_QUAD AS "s_2_1-t0"
OPTION (QUIETCAST)) AS "s_2_0_rbc"
1 Rows. -- 1 msec.
SQL> set sparql_translate off;
SQL> set explain on;
SQL> SELECT __ro2sq ("s_2_0_rbc"."p") AS "p" FROM (SELECT DISTINCT
TOP 100 __id2i ( "s_2_1-t0"."P" ) AS "p" FROM DB.DBA.RDF_QUAD AS
"s_2_1-t0" OPTION (QUIETCAST)) AS "s_2_0_rbc"
SQL> SELECT __ro2sq ("s_2_0_rbc"."p") AS "p" FROM (SELECT DISTINCT
TOP 100 __id2i ( "s_2_1-t0"."P" ) AS "p" FROM DB.DBA.RDF_QUAD AS
"s_2_1-t0" OPTION (QUIETCAST)) AS "s_2_0_rbc" ;
REPORT
VARCHAR
_______________________________________________________________________________
{
local save: ($22 "set_no", $23 "set_no_save")
Subquery 20
{
from DB.DBA.RDF_QUAD by RDF_QUAD_POGS 8.9e+07 rows
Key RDF_QUAD_POGS ASC ($25 "s_2_1-t0.P")
After code:
0: $28 "__id2i" := Call __id2i ($25 "s_2_1-t0.P")
5: BReturn 0
Distinct (HASH) ($25 "s_2_1-t0.P")
After code:
0: $21 "p" := := artm $28 "__id2i"
4: BReturn 0
Subquery Select(TOP 100 ) ($21 "p", <$27 "<DB.DBA.RDF_QUAD s_2_1-t0>"
spec 5>)
}
After code:
0: $44 "p" := Call __ro2sq ($21 "p")
5: BReturn 0
Select ($44 "p")
}
26 Rows. -- 1 msec.
SQL> set explain off;
As we can see, it is going to use the RDF_QUAD_POGS index which offers the best query plan construction basis.
It would be marginally faster if there was an index that started with GP, but the current 2+3 index scheme does not have such.
So it is almost a full table scan, which might not complete on most of our systems due to limits set in the INI file for Web accessible instances
Set the Execution timeout on the /sparql form to enable the Anytime paradigm:
- Go to a Virtuoso SPARQL Endpoint, e.g., the DBPpedia SPARQL Endpoint:
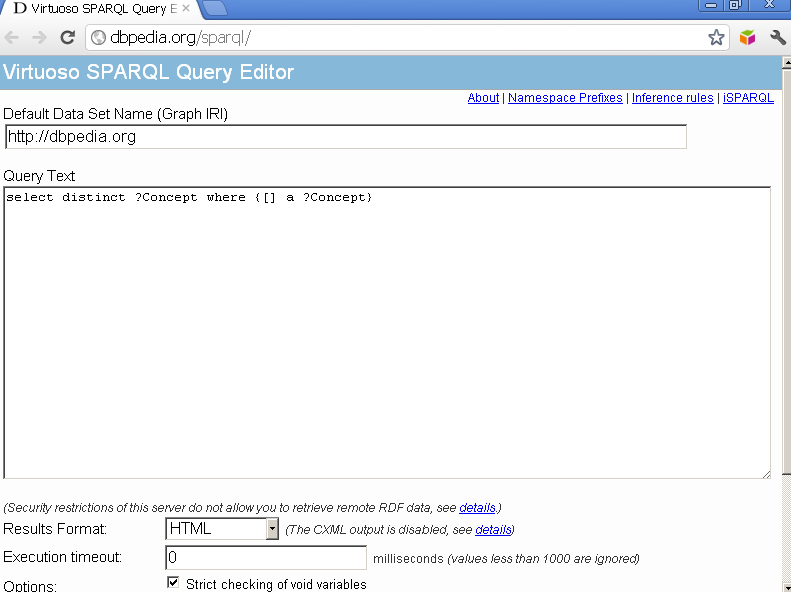
- Enter the query:
SELECT distinct ?p WHERE { ?s ?p ?o } LIMIT 100
- For "Execution timeout", enter
60000.
- Click "Run Query".
- You will be redirected to the following URL (containing parameter
timeout=60000), that presents the found results:
http://dbpedia.org/sparql/?default-graph-uri=http%3A%2F%2Fdbpedia.org&query=select+distinct+%3Fp%0D%0AWHERE%0D%0A{%0D%0A+%3Fs+%3Fp+%3Fo%0D%0A}%0D%0ALIMIT+100%0D%0A&format=text%2Fhtml&timeout=60000&debug=on

10000 (10 sec), you get only one unique ?p value back.
Using a timeout value of 60000 (60 sec) would still only show a few different values for ?p, which is logical considering that the index is sorted by Predicate (the P slot in the RDF triple pattern).
This means that once it gets the first unique ?p, it has to skip all the triples that have the same value of ?p, to get to the next one.
Using cURL
cURL Variant without the timeout parameter
$ curl -F "query=SELECT DISTINCT ?p WHERE { ?s ?p ?o } LIMIT 100" http://dbpedia.org/sparql
Virtuoso S1T00 Error SR171: Transaction timed out
SPARQL query:
define sql:big-data-const 0 SELECT DISTINCT ?p WHERE { ?s ?p ?o} LIMIT 100
cURL Variant using the timeout parameter
$ curl "http://dbpedia.org/sparql/?default-graph-uri=http%3A%2F%2Fdbpedia.org&query=SELECT+DISTINCT+%3Fp%0D%0AWHERE%0D%0A%7B%0D%0A+%3Fs+%3Fp+%3Fo%0D%0A%7D%0D%0ALIMIT+100%0D%0A&format=text%2Fhtml&timeout=60000&debug=on"
<table class="sparql" border="1">
<tr>
<th>p</th>
</tr>
<tr>
<td>http://www.w3.org/1999/02/22-rdf-syntax-ns#type</td>
</tr>
<tr>
<td>http://www.w3.org/2002/07/owl#equivalentClass</td>
</tr>
<tr>
<td>http://www.w3.org/2002/07/owl#sameAs</td>
</tr>
<tr>
<td>http://www.w3.org/2002/07/owl#equivalentProperty</td>
</tr>
<tr>
<td>http://www.w3.org/2000/01/rdf-schema#subClassOf</td>
</tr>
<tr>
<td>http://www.w3.org/2004/02/skos/core#broader</td>
</tr>
<tr>
<td>http://www.w3.org/2000/01/rdf-schema#comment</td>
</tr>
<tr>
<td>http://www.w3.org/2000/01/rdf-schema#label</td>
</tr>
<tr>
<td>http://xmlns.com/foaf/0.1/name</td>
</tr>
<tr>
<td>http://xmlns.com/foaf/0.1/nick</td>
</tr>
<tr>
<td>http://www.w3.org/2004/02/skos/core#prefLabel</td>
</tr>
<tr>
<td>http://www.w3.org/2003/01/geo/wgs84_pos#lat</td>
</tr>
<tr>
<td>http://www.w3.org/2003/01/geo/wgs84_pos#long</td>
</tr>
<tr>
<td>http://www.w3.org/2000/01/rdf-schema#domain</td>
</tr>
<tr>
<td>http://www.w3.org/2000/01/rdf-schema#range</td>
</tr>
<tr>
<td>http://www.w3.org/2002/07/owl#versionInfo</td>
</tr>
<tr>
<td>http://dbpedia.org/ontology/purpose</td>
</tr>
<tr>
<td>http://dbpedia.org/ontology/supplementalDraftRound</td>
</tr>
<tr>
<td>http://dbpedia.org/ontology/podiums</td>
</tr>
<tr>
<td>http://dbpedia.org/ontology/buildingStartDate</td>
</tr>
</table>cURL Variant using the timeout parameter with additional response header
In this example, the Response header contains X-SPARQL-MaxRows: 10000, which is used to indicate the maximum result set size of the instance, configured via [SPARQL] INI section entry.
For Anytime Query, it means that determining timeout that triggers response with additional headers (due to partial results) is based on the combination of MaxRows and QueryTimeout; i.e., only when Virtuoso cannot produce the ResultSet that matches MaxRows within QueryTimeout setting, will there be a timeout condition accompanied by addition response headers.
curl -I "http://dbpedia.org/sparql?default-graph-uri=http%3A%2F%2Fdbpedia.org&query=SELECT+*+WHERE+%7B+%3Fs+%3Fp+%3Fo+.+%7D&format=text%2Fhtml&timeout=2000&debug=on" HTTP/1.1 200 OK Date: Fri, 12 Dec 2014 20:51:29 GMT Content-Type: text/html; charset=UTF-8 Content-Length: 3804866 Connection: keep-alive Vary: Accept-Encoding Server: Virtuoso/07.10.3211 (Linux) x86_64-redhat-linux-gnu VDB X-SPARQL-default-graph: http://dbpedia.org *X-SPARQL-MaxRows: 10000* Expires: Fri, 19 Dec 2014 20:51:29 GMT Cache-Control: max-age=604800 Accept-Ranges: bytes